2020 年最具潜力 44 个顶级开源项目,含11 类 AI 学习框架、平台
这个网址指向了TensorFlow的开源项目仓库。
五、PyTorch star 35.8k fork 9k
PyTorch 是深度学习领域一个广受欢迎的框架,它与 TensorFlow 并列为该领域的两大有力竞争者之一。
PyTorch是一个机器学习框架,它具备开源特性,并且拥有两项核心优势,其一是在进行张量运算时能够借助GPU实现强大加速,其二是在构建深度神经网络时采用自动调整系统,该系统基于磁带技术;这些高级功能有助于提升从研究阶段到生产阶段的工作效率。
先前,OpenAI 官方公布了一项决定,即全面转向 PyTorch,打算把自身平台的所有框架都换成 PyTorch,这也更加凸显了 PyTorch 在深度学习领域的巨大潜力。
GitHub 地址:
这个网址指向的是名为pytorch的软件项目,它托管在github平台上,是一个开源的机器学习框架,开发者们可以在这里找到相关的代码和文档,方便进行研究和开发工作,并且社区活跃,经常有更新和贡献。
六、MXNET star 18.4k fork 6.5k
MXNet 是一种完备的深度学习系统,能够灵活编程,并且可以不断拓展,用以承载最新的深度学习算法,其网址为 https://mxnet.apache.org/。
MXNet 支持多种编程范式,比如命令式和声明式,并且兼容多种编程语言,例如 Python、C++、R、Scala、Julia、Matlab 和 JavaScript,它是一款安装简单、学习方便的开源深度学习框架,其中包含一个 Python 接口叫作 gluon,该接口能帮助开发者快速构建神经网络,同时也能实现高效的模型训练。
GitHub 地址:
这个网址指向一个名为MXNet的开源项目,该项目现处于Apache软件基金会孵化器的管理之下。
七、Sonnet star 8.1k fork 1.2k
Sonnet 是 DeepMind 推出的,基于 TensorFlow 的一个开源框架,能够用来建立结构复杂的神经网络模型。
Sonnet 主要目的是为了便于 DeepMind 开发的其他模型之间进行共享,它支持在内部其他子模块中编写模块,也支持在构建新模块时将其他模型作为参数传递,同时,它还提供了处理这些任意层次结构的工具,使得使用不同的 RNN 进行实验成为可能,整个过程不需要进行复杂的代码修改。
GitHub 地址:
这个网址指向一个名为sonnet的项目,它托管在deepmind的github账户下
八、DL4J star 11.5k fork 4.8k
DL4J 是一个开源的深度学习库,它用 Java 和 JVM 实现,能够处理多种深度学习模型。DL4J的一个核心优势在于它具备分布式处理能力,能够运行在Spark平台以及Hadoop系统上,同时兼容分布式CPU与GPU执行,借助Spark技术可以在多台服务器集群和多个GPU之间执行分布式的深度学习模型训练,从而显著提升模型运算效率。
DL4J 的主要特点在于,它的神经网络训练依靠成群的迭代并行运算完成,这一过程得益于 Hadoop 和 Spark 架构的支撑,同时采用 Java 语言,使得开发人员能够在安卓平台上进行程序构建。
GitHub 地址:
这个网址指向一个名为deeplearning4j的项目,它托管在github平台上,属于eclipse组织。
III . 适用于强化学习的工具
九、Gym star 19.6k fork 5.5k
Gym 是一个平台,可以用来创建和评估强化学习算法,其网址是 https://gym.openai.com/。
它不依赖 agent 的已有认知kaiyun全站登录网页入口,并且以 python 为核心编程工具,因此能够便捷地与 TensorFlow 等深度学习框架对接,同时能清晰地将学习成效通过图形化界面呈现出来。Gym 集合了众多可用于设计强化学习方案的测试场景(即环境),这些场景具备统一接口,支持开发通用型算法。
GitHub 地址:
https://github.com/openai/gym
最新版八点七千分叉了一千一百
一种依托于 Tensorflow 的平台,意在为新手上手以及资深强化学习专家们开发出一种既灵活又稳固,同时还能确保结果一致的先进方法。
这个框架的设计思路源自大脑里驱动奖赏与驱动力行为的核心机制「多巴胺受体」,它凸显了神经科学领域与强化学习探索之间深厚的渊源,同时作为一项研究强化学习算法快速建模的工具而存在。
GitHub 地址:
那个网址指向谷歌的dopamine项目仓库
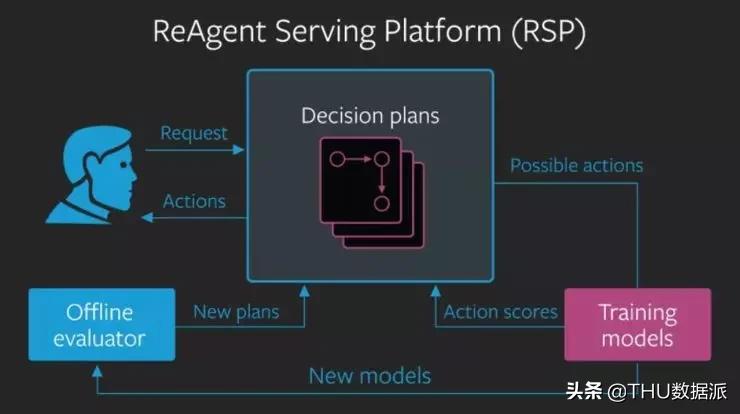
十一、ReAgent star 两千四百个版本,衍生出三百一十二个分支
Facebook 开发的一个模块化平台,实现端到端的决策推理系统,这个系统适用于强化学习、上下文管理等推理系统,能够大幅降低推理模型的设计难度。
ReAgent 包含三个主要构成部分,分别是负责制定决策并获取反馈结果的分析引擎,一个用于测试新系统运行效果的检测单元,以及一个能够实现快速更新的操作环境。它还是目前市场上功能最完备、组件化设计的人工智能推理系统开发平台,并且率先整合了策略验证机制,将有效推动各类决策支持系统的实施进程。
GitHub 地址:
这个网址指向一个名为ReAgent的项目,它托管在GitHub平台上,由Facebook的研究团队所维护。
十二、Tensorlayer star 五千九百个 分支 一千三百个
这是一个专供科研人员使用的深度学习与强化学习工具包。TensorLayer从基础到高级可划分为三个主要部分:神经网构建单元、任务执行单元、实用功能单元。
TensorLayer 在神经网络模块的抽象层面做得更加深入,跟 Keras 和 Pytorch 相比,它让运用既有层变得更容易,并且创建新层的过程也更为简便。
GitHub 地址:
这个网址指向一个名为tensorlayer的项目仓库,它托管在github平台上,里面存放了相关的代码和资料。
IV . 适用于自然语言处理的工具

十三、BERT star 21.3k fork 5.8k
BERT 是一种大型语言模型,采用双向 Transformer 架构构建而成,主要功能是对海量未标注文本资料实施预训练,目的是掌握一种语言编码方式,这种编码方式能够应用于特定机器学习课题的后续适配调整。
BERT 是自然语言处理领域的一项重大突破;如今,BERT 也是自然语言处理深度学习的关键构成,众多后续的自然语言处理模型都是依托于此进行优化和完善的。
GitHub 地址:
这个网址指向谷歌研究团队的BERT项目,是一个开源的预训练语言模型,主要用于自然语言处理任务,包括文本分类、命名实体识别、情感分析等,它基于Transformer架构,通过海量文本数据进行训练,能够生成高质量的文本表示,并在多种NLP基准测试中取得了优异的成绩,BERT模型的出现极大地推动了自然语言处理领域的发展,为后续的研究工作提供了重要的基础和参考。
十四、那个在Transformers里演出的明星,拥有21.7k的粉丝数量,同时,他的项目有4.8k的分支
转换器是神经机器翻译领域的一种神经网络,它着重于完成输入序列改写成输出序列的工作,这类工作涵盖了把声音信号变成文字信息,以及把文字内容转化为声音播报等任务。
完成此类工作要求具备「存储」能力,后续语句必须与前面句子的语境相衔接,这一点至关重要,否则会遗漏关键内容。借助将注意力机制集中于当前处理的词汇上,能够应对句子篇幅过长时,循环神经网络或卷积神经网络难以把握上下文和信息的挑战。
GitHub 地址:
这个网址指向一个开源的机器学习模型库,里面包含了多种预训练的深度学习架构,这些架构能够被应用于各种自然语言处理任务,比如文本分类、语言生成和问答系统等,用户可以通过这个平台方便地获取和使用这些先进的模型,从而加速自己的项目开发进程。
AllenNLP的星标数量达到八千,其分支项目有一千七百个
一个以 PyTorch 为基础的 NLP 实验平台,借助深度学习技术实现文本分析功能,借助对底层细节的精细操作,以及提供优质的示范代码,能够便捷高效地协助研究者开发新的语言解析系统。
AllenNLP 大幅简化了新型深度学习模型的构建与检验过程,几乎能够应对所有自然语言处理任务,借助若干核心模块,用户可以便捷地在远程服务器或个人计算机上执行模型运算。
GitHub 地址:
这个网址属于一个名为 allenai 的组织,该组织专注于开发 allennlp 这个项目,它是一个用于自然语言处理的库,提供了多种机器学习模型和工具,方便开发者进行相关应用的研究和实现。
十六、flair star 8.1k fork 1k
一个操作便捷的 Python 自然语言处理工具,能够将当前领先的 NLP 模型用于文本分析,包括识别命名实体、标注词性、解决词义模糊问题以及进行分类任务。
Flair 是一个基于 Pytorch 的自然语言处理平台,它的操作界面比较容易上手,能够让使用者整合多种词语表示和文本表示,涵盖了 Flair 表示、BERT 表示以及 ELMo 表示。
GitHub 地址:
这个网址指向一个名为flairNLP的GitHub仓库,里面存放着相关项目资料,内容丰富且持续更新,用户可以在这里找到许多有用的代码和文档,对开发者来说是个不错的资源平台。
该软件在GitHub上拥有十五万七千位关注者,同时有二千八百个分支项目
这是一套具备重工业级别的 Python 自然语言分析软件。它能够处理大量文本数据,拥有强大的功能模块,适用于各种语言处理任务,并且经过了严格的性能测试。
它已位列 Python 中应用最广的工业级自然语言框架之中,兼具当前最优的精准度与高效性,并且拥有一个充满活力的开源社群提供维护。
GitHub 地址:
这个网址指向一个名为spaCy的开源自然语言处理项目,托管在GitHub平台上,它提供了多种语言处理工具和功能。
十八、这个项目叫fastText, 版本号是20.5k, 跟进了3.9k次
FastText 是由 Facebook 人工智能研究实验室开发的一个开源文本处理工具包,该工具包专注于文本分类和文本特征提取,能够实现高效的文本分类和特征学习功能。
fastText 的关键在于它借助「词袋」模型,不考虑文本中的排列次序;该模型并非线性运作,而是通过构建层级分类器,将运算复杂度压缩至对数层次,同时在大规模且分类类别更多的情况下展现出更优性能。
GitHub 地址:
这个网址指向一个名为fastText的项目,它托管在GitHub平台上,由Facebook研究团队开发和维护,用于文本分类和表示学习任务,并且这个项目是开源的,任何人都可以访问和利用它提供的资源进行相关研究或应用开发。
V . 适用于语音识别的工具
十九、Kaldi star 8.2k fork 3.7k
Kaldi 是目前使用广泛的开发语音识别应用的框架。
这个语音识别软件包是用 C++ 制作的,科研人员借助 Kaldi 能够培养出语音识别神经网络,不过,要是想把训练出来的网络用在手机等移动设备上,往往得做很多转换适配的编程工作。
GitHub 地址:
这个网址指向一个名为kaldi的软件仓库,它托管在github平台上,主要用于语音识别相关的研究和开发工作,包含了大量的算法和工具,可以供开发者使用和改进,目的是构建更高效的自动语音识别系统。
二十、DeepSpeech 开源版本 13k 个分支,衍生出 2.4k 个分叉版本
DeepSpeech 是一款公开的语音识别软件,它采用了源自百度深度学习研究所论文的智能算法来构建模型。该系统借助了 Google 的 TensorFlow 框架,以此方便开发部署。
GitHub 地址:
这个网址指向的是Mozilla的一个项目,名为DeepSpeech,它是一个开源的语音识别引擎kaiyun官方网站登录入口,可以转换音频中的语音为文本,这个项目是建立在深度学习技术之上的,目的是为了提供一种更加高效和准确的语音识别解决方案,它允许用户通过命令行界面来使用,同时也提供了Python API接口供开发者调用,这个项目是免费提供的,并且源代码是公开的,任何人都可以下载并使用它来进行自己的语音识别任务,DeepSpeech可以处理多种格式的音频文件,包括WAV和FLAC等,它支持多种语言,包括英语、中文和西班牙语等。
二十一、wav2letter版本4.8k,存在770个分支
这是 Facebook 人工智能研究院首次公布的完整卷积自动语音识别解决方案,是一个便捷且高效的端到端自动语音识别(ASR)平台。
wav2letter 的主要构思遵循三项重要理念,具体表现为:能够快速训练处理拥有海量语音信息的庞大数据集,采用便于扩展的架构,方便集成新的网络设计、代价函数以及语音识别流程中的关键环节,同时确保语音识别方案能顺利从研发阶段迁移至实际应用部署。
GitHub 地址:
这个网址指向一个由脸书研究团队创建的项目仓库,该仓库专注于语音到文本的转换技术,内容包含了相关的代码和资料。
VI . 适用于计算机视觉的工具
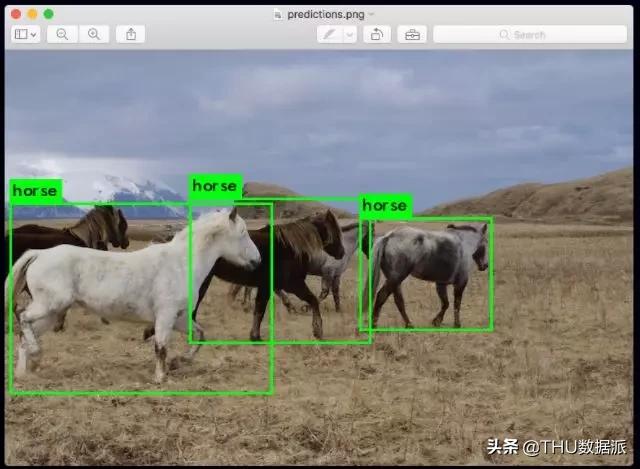
这个版本有22个字符,那个版本有10个字符
YOLO是深度学习里处理图像识别任务最顶尖的即时系统。它工作起来首先把图片划分成固定大小的格子,接着同时针对所有格子执行识别程序,以此判断里面包含哪些物体种类。分类完成后,它会自动把这些格子整合起来kaiyun全站网页版登录,在物体附近构成最合适的框线。
这些步骤同时开展,所以 YOLO 可以即时执行,并且每秒能分析四十幅画面。官网信息表明,在 Pascal Titan X 上,它以每秒三十帧的速度处理画面,同时在 COCO 测试开发中的 mAP 值达到百分之五十七点九。
GitHub 地址:
这个网址指向一个名为YAD2K的GitHub项目,由allanzelener创建和维护,里面包含了相关的代码和资料,方便开发者使用和研究。
它还引出了32.4k个分支
OpenCV 是英特尔公开发布的可以在不同系统上使用的计算机视觉软件包,被 CV 领域的开发者和研究者视为必备的软件工具。
这个资源是一系列集合了图像处理前期操作到模型调用等多项视觉功能的工具包,能够应对图像辨识、物体定位、画面划分以及人物追踪等核心视觉工作。它最突出的优势在于整合了整个工作流程的解决方案,所以使用者不必掌握各个环节的技术原理,就可以通过接口实现视觉应用的开发。它拥有 C++、Python 以及 Java 的衔接方式,兼容 Windows、Linux、Mac OS、iOS 和 Android 这些平台。
GitHub 地址:
这个网址指向一个名为OpenCV的计算机视觉库的GitHub存储库。
二十四、Detectron2 拥有七千七百个星标,被分叉了一千四百次
Detectron2 是 PyTorch 1.3 版本里一个重要的新增组件,它源自 maskrcnn 的基准测试,同时也是对早期 detectron 版本进行的全面革新。
Detectron2 采用创新式模块化构造,显著提升了其适应性及延展能力,它可以在单个或多个 GPU 服务器上实现更迅捷的训练进程,具备更强的变通性与拓展空间,同时优化了维护效能与规模适应性,旨在满足实际应用场景的需求。
GitHub 地址:
这个网址指向一个由脸书研究团队创建的项目仓库,内容是关于物体检测的框架,它包含了多种先进的算法和工具,主要用于计算机视觉领域的研究和应用,该项目的代码和文档都是公开的,方便开发者使用和学习。
二十五、OpenPose 星标十五万九千, 分支四万七千
OpenPose是一个开源的人体姿态识别库,由美国卡耐基梅隆大学(CMU)研制,该库采用卷积神经网络和监督学习方法构建,并依托于 caffe 框架实现功能。
该系统能够识别人的肢体动作、面部神态以及手指活动等体态信息,既可用于单人场景,也适合多人环境,并且非常稳定可靠。它是全球第一个运用深度学习技术进行实时多人平面体态测算的软件,目前许多体态分析案例都依托它来完成,包括动作捕捉、虚拟试穿、艺术创作辅助等用途。
GitHub 地址:
这个网址指向一个名为开放姿态的代码库,它是由卡内基梅隆大学的感知计算实验室所维护的,里面包含了相关的开源项目和研究资料。
二十六、facenet star 10k 分支 4.1k 跟随者
长卷积神经网络深度学习,将图像转换到欧氏空间,这种技术称作通用识别人脸方法。
这个系统能够从面部图像中获取精准的细节信息,这些信息被称为面部向量,它们能够用来构建人脸识别模型,进而完成身份确认功能。该系统在 LFW 数据集上的测试结果显示出 99.63% 的正确度,而在 YouTube Faces DB 数据集上的准确度则为 95.12%。
GitHub 地址:
这个网址指向一个GitHub上的项目,项目名称叫做facenet。
VII . 适用于分布式训练的工具

二十七、Spark MLlib 获得二十五千一星,有二十一万一千分叉
Spark属于一种公开的集群计算系统,同时也是当前数据加工作业中备受青睐的开放源代码软件品种
链接地址为https://spark.apache.org/mllib/,这个网址是官方的。
Spark运用了内存中处理方法,它在内存中的处理能力远超Hadoop MapReduce的处理能力,达到了百倍之差;这一优势也促使Spark MLlib分布式计算框架能够高效且迅速地执行任务。它能够执行多种机器学习任务,包括聚合分析、识别归类以及预测建模等操作,支持将信息载入到分布式计算环境中,便于反复检索和利用,因此十分契合机器学习应用场景。
GitHub 地址:
这个网址指向的是Apache软件基金会开发的Spark项目。
二十八、某个名为Mahout的软件版本达到一千八百个用户,其分支版本数量为九百三十个
Mahout 是一个分布式线性代数平台,能够迅速构建可扩展的高性能机器学习软件(http://mahout.apache.org/ )。
Mahout 框架原先常与 Hadoop 结合使用,不过其中不少算法也能脱离 Hadoop 执行。该框架支持多种算法在分布式 Spark 集群上执行,同时兼容 CPU 和 GPU 处理。
GitHub 地址:
这个网址指向的是Apache软件基金会维护的一个项目,该项目专注于开发机器学习相关的算法和工具,它为开发者提供了多种数据挖掘和数据分析的解决方案,并且这些功能都是基于开源模式进行共享的,社区成员可以在这里找到相关的代码库和文档资料进行学习和使用
二十九、Horovod star 八千五百,分支一千三百
这是一个由 Uber 开放源代码的分布式深度学习训练体系,它支持跨多台机器,让深度学习在分布式环境下能够迅速部署,并且操作起来更加便捷。
据说明,Horovod 使开发者用少量指令即可达成目标。这既提升了初次调整的效率,又使排错更为便捷。鉴于深度学习工程频繁更新,这种方式能显著减少时间投入。它不但融合了卓越性能,还擅长优化基础模型中的细微之处,比如:兼顾高级接口的应用,又借助 NVIDIA 的 CUDA 套件来开发专属运算单元。
GitHub 地址:
这个网址指向一个名为horovod的开源项目托管在github平台上
三十、Dask star 6.2k fork 994
当开发人员希望分布式处理时,可以借助 Dask 实现运算分配到众多核心,或者跨多台设备执行。
Dask 拥有处理数组、表格和列表的框架,适合在内存无法容纳的大数据集上实现并行操作。对于规模庞大的数据,Dask 提供的复杂集合可替代 NumPy 和 Pandas 的功能。
GitHub 地址:
https://github.com/dask/dask
三十一、Ray star 10.3k fork 1.5k
Ray 是一种先进的分布式作业执行系统,其采用了不同于常规分布式计算平台的体系结构和计算逻辑,旨在便捷高效地开发与部署分布式应用。
Ray 采用的是标准的主从架构模式。在这种模式下,主节点承担着整体统筹以及状态管理的工作,而从节点则专注于处理分布式的运算工作。但与常规的分布式运算系统相比,Ray 采用了融合多种任务调度方式的策略,因此运行效率更为出色。
GitHub 地址:
这个网址指向一个名为ray-project的GitHub仓库。
VIII . 适用于自动建模的工具
三十二、TPOT star 6.7k fork 1.2k
TPOT 是一款基于 Python 开发的软件工具,借助遗传学方法进行特征筛选和模型挑选,通过少量指令即可构建出完整的机器学习方案。
在机器学习模型的构建过程中,TPOT发挥着关键作用,它借助遗传算法,能够考察成千上万种不同的方案,目的是为模型和参数找出最优的搭配,进而实现机器学习过程中模型挑选和参数优化的自动化。
GitHub 地址:
这个网址指向一个名为tpot的仓库,它属于EpistasisLab组织。
三十三、AutoKeras 主分支六千六百个,分叉分支一千一百个
它使用了高效神经架构搜索(ENAS,
这个链接指向的论文arxiv.org/abs/1802.03268,安装该软件包非常便捷,只需执行pip install autokeras命令即可,随后便可以利用个人数据集开展专属的架构探索工作,实现个性化的构建方案。
与谷歌 AutoML 相比,两者在构建方法上大致相同,但存在差异,即 AutoKeras 的全部代码均为开源,开发者可以免费利用。
GitHub 地址:
这个网址指向一个名为autokeras的开源项目,它属于keras团队维护,主要功能是自动化神经网络设计,通过这个平台可以简化深度学习模型的构建过程,用户无需手动调整大量参数,系统能够自动优化网络结构,从而提高开发效率,并且该项目托管在github上,方便开发者获取和贡献代码
三十四、Featuretools 星标 4600 分支 602
这是一个用于自动化特性工程的开源 python 框架(
这个网址是featuretools的官方网站链接。
它能够协助程序员依据若干关联数据表自动生成特征,程序员只需掌握数据表的基础构造以及它们之间的联系,并在一个称为实体集合(一种数据构造)的框架内进行标注,接着借助一种称作深度特征合成(DFS)的技术,单次函数调用即可创建成千上万个特征。
GitHub 地址:
这个网址指向一个名为featuretools的GitHub项目,它由FeatureLabs组织维护,里面包含了相关的研究成果和代码实现,主要聚焦于使用自动化特征工程来提升机器学习模型的性能表现,为数据科学家和开发者提供了实用的工具和资源,可以方便地集成到他们的工作流程中
三十五、NNI star 5.3k fork 683
NNI 是微软开发的一个开源工具包,专用于神经网络的超参数优化,同时也是当前颇受欢迎的 AutoML 开源项目。
新版 NNI 对机器学习全过程提供了更周到的辅助,涵盖:数据预处理、网络结构探索、参数优化以及模型精简,使用者可借助自动化机器学习技术达成,即便是不熟悉开发的人也能便捷操作。
GitHub 地址:
这个网址指向微软的开源项目,名为神经架构搜索,它是一个自动化机器学习框架,用于高效地设计新型神经网络架构,用户可以通过它来探索和优化模型结构,从而获得性能更优的解决方案,该项目托管在GitHub平台上,方便开发者获取和使用相关资源。
三十六、AdaNet star 3k fork 443
AdaNet 是谷歌公开发布的一个小型化系统,它依托于 TensorFlow 这个软件库,
该网址指向adaNet的官方文档,版本为0.8.0。
AdaNet 操作简便,能够构建出性能优良的模型,帮助机器学习从业者节省了挑选最优神经网络体系的时间,并且运用了一种自适应方法,将学习神经网络结构视为对子网络模块的集合进行优化。
相关文章
-

kiayun手机版登录app游戏登录入口.手机端安装.cc 湖南万通汽修学校:紧抓生命线,教学质量严把关!
-
kiayun手机版登录app游戏登录入口.手机端安装.cc 吃鸡国际服地铁逃生模式
-
kiayun手机版登录下载 各地供销合作社:扎实推进“八代会”部署要求落地生根
-
kiayun手机版登录下载 吉林省金融业官方网站
-
kiayun手机版登录app游戏登录入口.手机端安装.cc 广西壮族自治区村民合作社章程(示范稿)
-
kiayun手机版登录 西藏自治区实施《中华人民共和国农民专业合作社法》办法
-

开·云体育app下载安装 美图秀秀照片拼图
-
kiayun手机版登录app游戏登录入口.手机端安装.cc 美图秀秀会员版