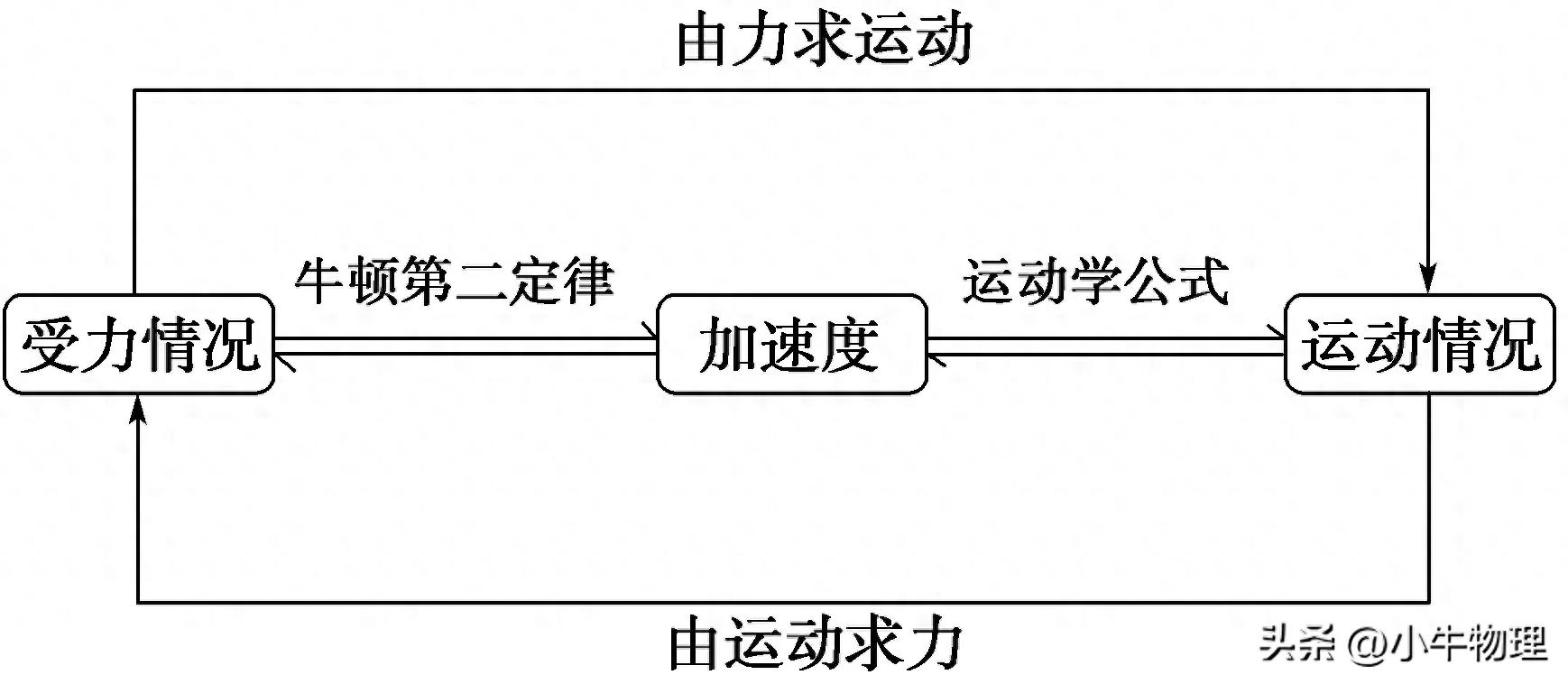
用Python可视化卷积神经网络
这无法保证,甚至没有表明,新出现的案例会被准确归类。神经网络或许已经“掌握”了100种仅适用于特定情况而不适用于任何新问题的特殊情况。值得注意的是,研究人员最初拍摄了200张图像,其中100张是坦克,另外100张是树木。他们仅在训练中使用了其中的50个。科研工作者针对剩余的一百幅图像运用了神经网络,该网络未经额外学习便准确识别了全部剩余照片。太棒了!他们把研究成果提交给五角大楼,总部迅速将任务返还,他们反映,在自己的检测中,该网络在图像分辨上效果与随机猜测相仿。

调查表明,研究者收集的图片资料中,经过伪装的坦克图像多是在阴天环境下拍摄的,而未伪装的图片则多是在晴天条件下拍摄的。人工智能系统已经掌握了识别阴天与晴天的能力,但并未学会分辨伪装坦克和裸露的森林。
CNN模型的可视化方法
CNN模型的可视化手段,依据其内在运作机制,能够划分成三个主要类别
后续章节将具体阐述这些内容。现阶段,我们选用keras作为工具来建立深度学习模型开元棋官方正版下载,同时借助keras-vis进行模型的可视化工作。开展下一步之前,务必确认相关程序已正确安装在您的系统中。
本篇内容基于“识别数字”比赛所提供的数据集展开。要执行后续代码kaiyun全站登录网页入口,需先将其下载至本地系统。另外,在着手进行以下实现步骤前,请务必先完成所给出的准备工作。
数据集:
这个链接指向一个数据分析竞赛的页面,该竞赛的主题是识别数字图像,比赛主办方是Analytics Vidhya,网址为datahack.analyticsvidhya.com,具体活动页面为contest/practice-problem-identify-the-digits。
准备步骤:
这个网址是一个提供Keras脚本资源的网站,网址为https://www.analyticsvidhya.com/keras_script-py/,里面包含了相关的教程和代码示例,对于想要学习Keras的用户来说是一个不错的参考来源。
1.基本方法1.1 绘制模型架构
最直接的做法是输出模型信息。通过这种方式,你可以查看神经网络的每一层的大小以及各层的参数数量。
在keras中,可以按如下方式实现:
model.summary()
那个东西非常巨大,令人感到十分震惊,它静静地躺在那里,周围没有任何动静,仿佛已经存在了很久很久,没人知道它的来历,也没有人见过它的样子,它就像一个谜团,吸引着所有人的目光,却又无人能够解开它的秘密。
类别 (属性) 结果尺寸 参数数量
那个东西非常巨大,几乎无法想象它的尺寸,它静静地躺在那里,周围没有任何动静,仿佛时间都凝固了,这种景象让人感到无比震撼,难以用言语形容。
卷积层一,类型为Conv2D,输出维度为无,高为26,宽为26,通道数为32,参数总量为320个
_________________________________________________________________
卷积层二,类型为Conv2D,输出维度为无,尺寸为24x24,通道数为64,参数数量为18496个。
_________________________________________________________________
最大池化层一,对输入进行降维处理,输出维度为十二乘十二乘六十四,参数数量为零,
_________________________________________________________________
dropout_1这个层采用了Dropout技术,其输出维度为None, 12, 12, 64,没有参数数量,
_________________________________________________________________
展平_1 (展平) (无, 9216) 零
_________________________________________________________________
密集层一,Dense类型,输出维度为一百二十八,参数总量为一百一十七万九千七百七十六
_________________________________________________________________
dropout_2模块被激活了,它是一个dropout层,当前没有连接任何输入,输出维度是128,索引编号为0,。
_________________________________________________________________
预测值(密集层) (空,10) 1290
=================================================================
Total params: 1,199,882
Trainable params: 1,199,882
Non-trainable params: 0
为了提升创作能力与表现水平,你可以构建一个框架示意图,借助keras.utils.vis_utils功能实现
1.2 可视化滤波器
还有种方式是画出学习系统里那些筛选工具的样子,这样就能明白这些筛选工具是怎么运作的。比如,前面说的那个系统,它第一组里的头一个筛选工具长这样。
top_layer = model.layers[0]
图像显示第一层权重矩阵的第一个通道,采用灰度色彩映射
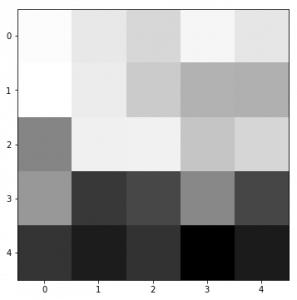
通常情况下,低层滤波器发挥着轮廓识别的功能,随着层级提升,它们更擅长识别物体和面部这类高级特征。
2. 基于激活的方法2.1 最大激活
要弄清我们的神经网络在执行什么任务,可以对输入的图片施加过滤器,然后展示其结果,这样就能明白何种类型的输入特征会触发某个特定的过滤器,比如,某个过滤器专门针对人脸,一旦图像中出现了人脸,它就会响应。
在可视化激活函数中获取激活图像
from vis.utils import utils
from keras import activations
在matplotlib库中导入pyplot模块并将其命名为plt,
%matplotlib inline
设置图像的宽度和高度分别为18和6单位,通过调整参数完成
# 按名称搜索图层索引。
# 或者,我们可以将其指定为-1,因为它对应于最后一层。
layer_idx通过调用utils模块的find_layer_idx函数获得,该函数以模型对象和字符串'preds'作为参数输入
#用线性层替换softmax
当前模型的第layer_idx层激活函数设置为线性激活函数
模型经过工具类处理,应用了相关调整,完成了更新
# 这是我们要最大化的输出节点。
filter_idx = 0
图像 = 展示模型激活情况,针对指定层级,并选取特定过滤器索引进行可视化
plt.imshow(img[..., 0])
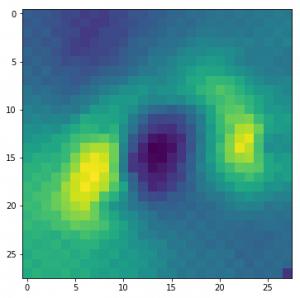
我们可以把这个想法转移到所有的类中,并检查每个类。
PS:运行下面的脚本来检查它。
对于每一个输出索引值,从零到九进行遍历,依次处理
# 让我们这次关闭详细输出以避免混乱
图片 = 生成模型激活可视化结果, 使用指定层级编号, 显示目标过滤器组, 数据值限定在零到一范围之间
plt.figure()
图标题为该网络的认知情况,具体内容为{}
plt.imshow(img[..., 0])
2.2 图像遮挡
在图像分类任务里,一个关键问题是模型能否准确判断图像中对象的具体位置,还是仅仅依赖周边环境信息。前面已经简要提及了基于梯度分析的手段。遮挡技术则尝试通过逐一用灰色方块遮盖输入图像的不同区域来探究这一问题,同时观察分类器的反应。实例显著揭示,机器正在画面中识别物体,由于一旦物体受到阻碍,它判定为该物体所属正确种类的可能性大幅度变小。

要明白这个原理,我们先从资料库中随意选出一幅图画,接着试着生成它的热力图,这样就能直观地知道画面哪些区域对区分内容最为关键。
进行图像遮挡迭代处理,设定尺寸参数为八
遮挡值等于一个五倍尺寸的矩阵,每个元素都是0.5,数据类型为浮点数
occlusion_padding = size * 2
# print('padding...')
图像经过填充处理后,其边缘增加了空白区域,具体表现为在四周分别添加了若干行和列,这些新增的部分被设定为特定的数值,从而使得原始图像的尺寸得到了扩展,内部内容则被保留了下来,同时保持了原有的清晰度和比例关系
遮挡填充,遮挡填充,零,零
), 另一个参数为恒定值, 该值设定为0
对于每一个y坐标,从遮挡填充的边界开始,到图像高度的另一侧加上填充的边界结束,按照指定的尺寸进行步进,进行遍历
对于图像的每一列,从偏移量开始,每隔指定步长进行遍历,直到覆盖整个宽度范围
tmp = image_padded.copy()
tmp从y减去遮挡边缘宽度开始到y加上遮挡中心高度再加遮挡边缘宽度结束,横向上从零到x的长度,
x 减去遮挡填充,到 x 加上遮挡中心宽度再加遮挡填充
= occlusion
临时数据区域中从y开始到y加上遮挡中心高度的部分,以及从x开始到x加上遮挡中心宽度的部分,被替换为遮挡中心图像内容
得到 x 减去遮挡填充, y 减去遮挡填充,
临时数据从遮挡填充边界之后到临时数据高度减去遮挡填充边界,从遮挡填充边界之后到临时数据宽度减去遮挡填充边界,提取中间部分内容
i = 23 # 例如
data = val_x[i]
修正类别等于验证标签中最大值的索引位置
# model.predict的输入向量
将数据调整为单张图像,尺寸为28x28,深度为1层,并存储在变量inp中
# matplotlib imshow函数的图片
img = data.reshape(28, 28)
# 遮盖
img_size = img.shape[0]
occlusion_size = 4
print('occluding...')
创建一个全零的浮点型数组,其形状为图像尺寸的平方,并将这个数组赋值给变量heatmap
创建一个全零数组,形状为图像尺寸,数据类型为十六位整数,并将其赋值给变量class_pixels,每个元素初始值为零,数组整体呈正方形结构,边长等于图像的尺寸值
在众多数据结构中,有一种叫做字典的结构,它能够存储不重复的键值对,每个键都对应一个值,这种结构在处理数据时非常方便,它允许我们通过键快速找到对应的值,而不需要遍历整个结构,这种字典结构在Python中可以通过defaultdict类来实现,它能够自动为不存在的键提供默认值,从而简化了代码的编写,提高了代码的效率,在collections模块中,defaultdict是一个非常有用的工具,它能够帮助我们更好地管理数据,提高程序的运行效率。
counters = defaultdict(int)
通过枚举函数iter_occlusion遍历数据集data,每次返回一个索引n,以及一个包含坐标x和y,以及浮点数图像img_float的元组,其中occlusion_size指定了遮挡区域的大小
X通过调整形状变为单张图像,尺寸为28x28像素,并增加一个通道维度
out = model.predict(X)
输出最大值索引为,预测结果为,置信度为,正确类别标签为
输出x起始点至终点范围,以及y起始点至终点范围,用竖线隔开,各范围均以对角线方式表示,起始点与终点坐标依次排列,中间用空格分开
该热力图区域等于输出结果的首个元素中正确类别的值,起始点位于y坐标,长度为遮挡尺寸,终止点位于x坐标,宽度也为遮挡尺寸
当前区域像素值赋值为输出数组最大值索引所在位置,横坐标为x,纵坐标为y,遮挡区域宽高均为occlusion_size
counters[np.argmax(out)] += 1
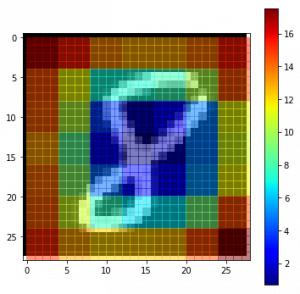
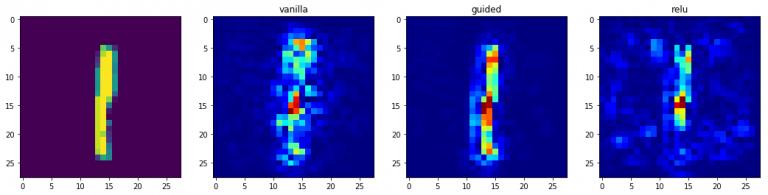
3. 基于梯度的方法3.1 显著性图
通过坦克的实例开yun体育app官网网页登录入口,我们能够明白我们的模型究竟在哪个部分进行预测,要确定这一点,我们可以借助显著性图
理解显著性图的核心在于一个简单的计算过程,即确定输出分类和图像数据之间的梯度关系。这个计算旨在揭示输出分类值如何随着图像像素的轻微调整而波动。所有正值梯度都表明,对某个像素的细微改动会提升输出数值。因此,将这类梯度以图像的形态呈现出来,能够帮助人们形成直观的认识。
直观地,该方法突出了对输出贡献最大的显著图像区域。
class_idx = 0
indices是使用np.where函数得到的索引列表,该函数检测val_y二维数组中指定类别的元素是否等于1,然后返回满足条件的元素索引,最后通过[0]获取数组形式的结果
# 从这里选取一些随机输入。
idx = indices[0]
# 让sanity检查选中的图像。
from matplotlib import pyplot as plt
%matplotlib inline
plt.rcParams['figure.figsize'] = (18, 6)
展示第 idx 个验证图像的第一通道内容,通过图像显示函数实现
从可视化技术中导入生成显著性的功能
from vis.utils import utils
from keras import activations
# 按名称搜索图层索引
# 或者,我们可以将其指定为-1,因为它对应于最后一层。
layer_idx = utils.find_layer_idx(model, 'preds')
# 用线性层替换softmax
model.layers[layer_idx].activation = activations.linear
model = utils.apply_modifications(model)
生成的梯度通过可视化显著度函数获得,该函数作用于模型,选取特定层级索引,并指定过滤器的索引为类别索引,同时以验证集的指定输入作为种子输入
# 可视化为热图。
用图像显示梯度,颜色映射采用jet模式
# 这对应于线性层。
对于类别索引从零到九的每一个值
indices是使用np.where函数获取的,该函数查找val_y数组中class_idx指定列元素等于1的所有行索引,然后返回这些行索引的列表
idx = indices[0]
f, ax = plt.subplots(1, 4)
ax的第一个元素显示验证数据集中指定索引处第一通道的图像内容
通过列举,依次获取列表中的每个元素,包括空值,以及两个特定的字符串,并赋予它们不同的标识符,同时记录它们的位置顺序,每个元素之间用逗号分隔,最后一个元素后加句号
grads = 计算梯度并可视化模型, 指定层级编号, 选择特定过滤器索引,
输入数据等于val_x中索引为idx的值,反向传播修正等于modifier
if modifier is None:
modifier = 'vanilla'
ax[i+1].set_title(modifier)
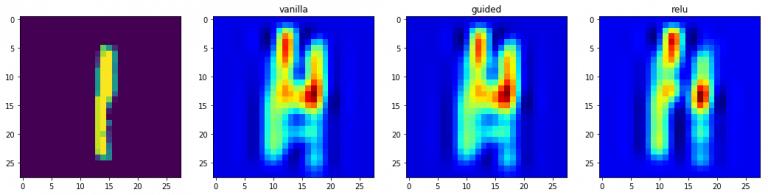
3.2 基于梯度的类激活图
类激活图是另一种可视化模型预测过程的方法,通过观察倒数第二卷积层的输出实现,而不是利用相对于最终结果的梯度信息,目的是为了有效利用倒数第二层所保留的空间细节特征。
在可视化技术中,调取视觉化功能,用于图像识别分析
# 这对应于线性层。
for class_idx in np.arange(10):
indices是满足条件val_y数组第class_idx列元素值为1的所有行索引的集合,通过np.where函数获取,结果以数组形式返回,最后通过索引[0]取出数组本身
idx = indices[0]
f, ax = plt.subplots(1, 4)
ax中的第一个元素使用函数显示val_x索引指定位置处第一个通道的数据
对于列表中的每个元素,按照顺序进行遍历,依次获取当前元素的索引和值,其中列表包含空值、引导词和激活函数名称
grads = 通过模型可视化技术获取特定层级,选取目标类别索引对应的过滤器,计算并展现梯度信息,
输入参数为种子值,即val_x的索引值,同时传入反向传播的修正参数modifier
if modifier is None:
modifier = 'vanilla'
ax[i+1].set_title(modifier)
ax[i+1].显示图像 grad, 使用 颜色映射 jet
结尾
本文阐述了CNN模型的可视化方法,并说明了进行可视化的原因,通过一个实例来具体演示,这种方法用途广泛。