解读2018:我们处在一个什么样的技术浪潮当中?
最近,关于经济寒冬的说法日益增多,身边有不少互联网企业进行了裁员,越是处于寒冬时期,我们越需要去了解趋势,找准前进的方向。在过去几年里kaiyun.ccm,互联网领域各种“风口”不断涌现,究竟哪些才是真正的趋势呢?在这篇文章中,我将尝试对当前互联网技术的发展展开分析,找出其背后的原因与逻辑。
要是你长时间追踪本领域的前沿技术,你就会发觉,近十年间互联网技术出现了极为巨大的改变,这种改变差不多在每一个领域都有发生:
在软件架构领域,经历了从单体应用到 SOA 再到微服务;
在云计算领域,经历了从虚拟机到容器;
除此之外,还有一些新兴领域,比如AI、区块链,它们一开始不受重视,后来成为显学,还开启了一波又一波的风口。
单独去审视这些领域的发展情况,会感觉纷繁复杂毫无头绪,然而要是从整体角度去看待,就会发觉它们彼此之间存在联系,它们的发展源自一种共同的推动力量,并且遵循着相似的逻辑。
如果要给这个推动力、给今天的这个技术浪潮取一个名字,在当前阶段我认为可以采用“云原生”,然而这个短语在各种营销语境中被过度运用,它的定义会出现偏差,所以后文我不会使用这个短语,而是使用真正的云计算这句话。
我们当前技术浪潮有着真实的含义,那便是我们正迈向真正的云计算时代,其他领域的发展都源于此,若要更具体些,便是:
云计算的技术逐渐发展成为它本来该有的模样;
以及与这样的云所匹配的软件架构;
以及与这样的架构所匹配的开发流程与方法论。
下面,我会分析几个主要的技术领域,从它们的发展历程来论述。
一、云计算:从虚拟化到容器到 Serverless
先从云计算说起。
2005年,亚马逊发布了AWS,这一行为算是拉开了云计算的序幕。然而,在相当长的一段时间内,云计算都未能实现其“自动扩容、按使用付费”的宣传内容 。
云计算最重要的技术是分布式计算与分布式存储,在分布式计算方面,最初的技术是虚拟化,即“Software defined xxx”,它通过对计算、存储以及网络资源进行虚拟化,进而能够为用户随意分配资源。但这里面一开始做得最好的是文件存储这一块,AWS S3以及类似的对象存储产品给人们带来了云时代的一些实际体验,然而云服务器却还是走回了卖服务器的老路。
这里的云服务器与传统服务器相比是有优势的,至少在运维时,不需要跑到千里之外的机房去排查问题。然而,它与我们期望的云服务相比差距甚远,它仅仅是传统技术向云时代过渡的替代品。虚拟化技术新建服务器耗时久,在扩容方面存在很大限制,容器技术诞生后,才最终解决了这一问题。但现在一些微型虚拟机开始出现,例如亚马逊网络服务刚刚发布的FireCracker,它试图融合虚拟机与容器的优点,这也是当前云计算技术的一个重要关注点。
分布式存储可分为文件和数据库,文件通过对象存储的方式早已得到解决,数据库却面临漫长的发展过程,传统数据库需要向分布式架构转变,同时会发现云计算厂商成为了数据库的研发主力,这些新数据库天生就是分布式的,或者天生就支持云计算特性 。
在云计算发展进程中,有一个分支是PaaS,最早在2007年推出了Heroku,从形态方面讲,它是一个App Engine,能提供应用的运行环境 。PaaS的理念被视作更接近真正的云计算,要是你使用虚拟化的云服务器,那你依旧得自己负责应用分发,负责应用部署,负责应用运维,还得与各种底层接口打交道,与各种底层资源打交道,而在PaaS上,这些都无需操心了,你只需把应用上传到云端即可。
但是,之前的PaaS体验不太好,容易导致平台绑定,很难支持大型应用,因此没有成为主流,这些问题直到Kubernetes出现后才得到解决。
在2015年之前,OpenStack是云计算的主流技术,许多公司包括IBM和红帽都在它上面投入了大量资金。然而,一些曾经天真乐观的公司,比如思科,试图基于OpenStack进入公有云市场,但在现实面前很快失败了。此外,主要参与者Nebula的关闭,也让市场信心遭受了严重打击。Docker迅速崛起,Kubernetes也快速崛起,在此情况下,OpenStack的声势已远不如从前 。
然而在这么多厂商的支持下,OpenStack 就无敌了吗?看似紧密的社区与厂商之间的关系,在容器这个新的技术热点面前被轻松击破,厂商不再是 Pure Play OpenStack,社区贡献排名也不再被提及。——唐亚光 《OpenStack 七年盘点,热潮褪去后的明天在哪?》
但是,Kubernetes处于过于底层的位置,真正的云计算并非是向用户提供Kubernetes集群 。
2014年,AWS推出了Lambda服务,Serverless开始成为热门词汇,从理论角度讲,Serverless能够做到NoOps,能够实现自动扩容,还能够按使用付费,它也被视作云计算的未来。但是,Serverless本身存在一些问题,比如冷启动性能问题难以解决,因此,围绕Serverless的研发是当前的前沿课题,将Serverless和容器技术融合也是当前的前沿课题。
Serverless是我们过去25年在SaaS领域迈出的最后一步,因为我们已逐渐把越来越多的职责交付给服务提供商 。——Joe Emison 《为什么Serverless比其他软件开发方法更具优势》
二、架构包含微服务,还有 Service Mesh,以及 Serverless 。
云计算为应用构建了分布式的基础设施,然而,要是应用依旧按照传统单体应用的思路来开发,那么云计算的意义就不太显著了。
这些年,软件架构渐渐从SOA演进到微服务,不少人觉得微服务是一种细粒度的SOA,去掉SOA里的ESB后,微服务变得更灵活,性能也更强。然而,实施微服务需要一些前提条件。
Martin Fowler曾总结过,微服务实施的前提涵盖:
这基本上就是Kubernetes起到的主要作用,尽管Spring Cloud、Dubbo微服务框架在各方面已十分完善,然而随着云原生计算基金会不断壮大,基于Kubernetes的微服务在社区中的热度日益升高,进而开始有许多公司利用这一套技术栈来构建微服务。
到2016年,Service Mesh开始受到社区关注,Kubernetes与Service Mesh相结合,再加上CNCF的一些开源项目,基于k8s的微服务技术栈基本得以完善。2018年,Istio 1.0发布,这进一步推动了相关发展,在未来,微服务领域将由k8s和Service Mesh主导。
Service Mesh:下一代微服务?
微服务正处在渐渐迈向巅峰的进程里,然而它的挑战者已然现身。Serverless也就是FaaS最初仅是AWS推出的一项功能,不过随着社区以及业界的跟进,渐渐有人把它视作微服务的进化 。其逻辑十分简单,从SOA到微服务,是一个服务粒度逐渐被拆分得更小的过程,FaaS里的Function可被视作更小的、原子化的服务,它天然契合微服务里的一些理念。
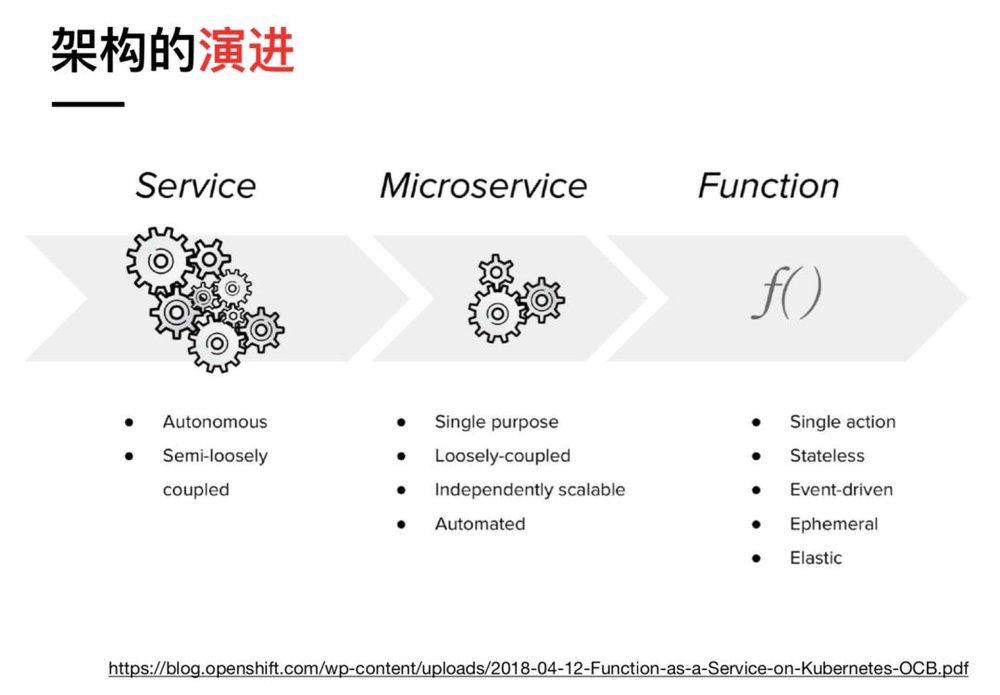
(许晓斌 《从微服务到 FaaS》)
当然,对于Serverless怎样融入现有架构,当前尚无成熟经验,Serverless自身也有一些问题,不过毫无疑问这是业界关注的重点。
三、数据库:从 NoSQL 到 NewSQL
在过去几年,数据库的发展同样令人瞩目。
2009年,MongoDB开源,这掀开了NoSQL的序幕,一时间,NoSQL的概念受到人们追捧,MongoDB也凭借其易用性在社区迅速普及。NoSQL抛弃了传统关系数据库中的事务和数据一致性,所以在性能上取得了极大提升,而且它天然支持分布式集群。
然而,不支持事务一直是 NoSQL 的痛处,致使它没办法在关键系统里使用。2012 年,Google 发表了 Spanner 论文kaiyun全站登录网页入口,从这以后,既支持分布式又支持事务的数据库渐渐诞生,以 TiDB、蟑螂数据库等作为代表的 NewSQL 兼具传统关系数据库和 NoSQL 的长处,开始显露头角。
从当前已有的SQL数据库实现方案来讲,NewSQL应当是最契合云数据库理念的实现。NewSQL自身拥有SQL、ACID以及Scale的能力,天生就具备了云数据库的某些特点。然而,从NewSQL迈向云数据库,仍然存在诸多有待挑战的难题,诸如多租户、性能等 。——崔秋《云时代数据库的核心特点》
本来事情发展到这里就结束了,然而在2014年,亚马逊推出了一个重磅产品,它就是基于新型NVME SSD虚拟存储层的Aurora,该产品实现了超大单机数据库,此数据库完全兼容MySQL,甚至连MySQL的bug都能兼容,并且在性能上比之前高出5倍以上 。(关于Amazon Aurora的读后感链接:https://zhuanlan.zhihu.com/p/30159571)
另外,各种不同用途的数据库纷纷诞生,并且取得了较大的发展,例如用于LBS的地理信息数据库,用于监控和物联网的时序数据库,用于知识图谱的图数据库等 。
可以这么讲,数据库如今处在一个百家争鸣的时期,并且因为云厂商付出的努力,基本上新出现的数据库都具备自动扩容、按使用付费这些云计算的特性 。
四、大数据:从批处理到流处理
Google在2003年到2006年期间发布了三篇论文,分别是关于GFS、BigTable、MapReduce的,这开启了大数据时代。在发展的早期,诞生了以HDFS/HBase/MapReduce为主的Hadoop技术栈,该技术栈一直延续到今天。在这当中,不少组件是可以替换的,甚至有的组件发生了换代。这其中,最重要的换代就是处理引擎。
最开始大数据的处理大多采用离线处理方式,MapReduce理念虽好,但其性能不佳,新出现的Spark抓住了这一契机,凭借其强大且高性能的批处理技术,成功取代了MapReduce,成为主流的大数据处理引擎。
随着时代不断发展,实时处理的需求日益增多,Spark推出了Spark Streaming,通过微批处理来模拟准实时的情况,然而在延时方面仍不尽如人意。2011年,Twitter的Storm吹响了真正流处理的号角,Flink将其发扬光大。
到现在,Flink不再仅仅把自己看作是流计算引擎,而是视为更为通用的处理引擎,并且开始正面挑战Spark的地位。
Apache Flink被业界公认为是最好的流计算引擎,然而它的计算能力不局限于流处理,其定位是一套具备流、批、机器学习等多种计算功能的大数据引擎,最近一段时间,Flink在批处理以及机器学习等大数据场景有长足突破。请你提供一下具体需要改写的句子内容呀,这样我才能按照要求进行改写。
Hadoop 本身也遭遇了 Kubernetes 的挑战。Hadoop本身包含专用于处理大数据的编排系统,比如Yarn等,不过像Spark、Presto、Kafka等最重要的Hadoop技术,如今已经能够在Kubernetes上运行,利用Kubernetes来运行大数据技术栈,能够更好地与其它业务进行集成。遭遇挑战的表现之一是,Hadoop技术栈有两家主要提供商,分别是Cloudera和Hortonworks,最近它们决定合并,缓慢的增长表明市场已无法容纳两家提供商了。《Kubernetes 会击沉 Hadoop 这艘船吗?》:https://thenewstack.io/will-kubernetes-sink-the-hadoop-ship/
五、运维:从手工运维到 DevOps
云计算技术在过去几年对运维造成了强烈冲击。依赖云计算提供商的公司,其运维职责被大大削弱。而在自研云技术的公司中,对运维的要求大幅提高。以往的经验已难以适用。
这其中最重要的变化就是DevOps出现了,运维的身份职责发生了转变,运维不再是专门跑任务脚本的人,也不再是专门与机器打交道的人,运维变成了OpenStack的专家,运维变成了Kubernetes的专家,运维通过搭建相关的分布式集群,为研发提供可靠的应用运行环境,运维通过管理相关的分布式集群,为研发提供可靠的应用运行环境。
DevOps 更重要的是改变了应用交付流程,从传统搭火车模式转变为持续交付,应用的架构变了,形态也变了,其方法论也跟着改变,DevOps 和持续交付还被视作云原生应用的要素。
至于AIOps是DevOps在实践AI过程中的应用,它称不上是范式的改变,并且AI在运维领域远远取代不了人的作用。
六、前端:前后端分离
前端在过去几年发生了翻天覆地的变化,2008年Nodejs出现,它彻底激发了前端的生态,它把JavaScript的疆域拓展到服务端和桌面,最终催生出大前端的概念。
若单纯审视传统前端开发的演变,主流技术已从 jQuery 转变至三大框架,更为关键的是,SPA 已然出现,前后端分离也已出现。
SPA意味着前端应用化,也就是胖客户端,部分业务逻辑可从服务端转移至客户端完成。前后端分离使前端从后端独立出来,划定了领域边界。对前端而言,后端成为数据层,只要接口能正确返回数据,前端不在意后端如何实现 。
事实上,胖客户端的转变恰好与后端的进化方向相符。不管是微服务还是Serverless,都着重强调无状态。这表明你不应该依靠后端去生成有状态的UI,而是要让客户端自己来处理状态。
从前后端分离看阿里 Web 应用架构演变
互联网分层架构,为啥要前后端分离?
前端发展出了一些技术,这些技术包括TypeScript、Redux/MobX、WebAssembly、WebWorker等,目的是应对越来越大型的客户端代码,这些技术也是前端重点关注的 。
七、AI:互联网的新基础设施
现代的AI是基于大数据与机器学习的,在许多公司中,大数据和AI归属于同一个数据科学团队。在过去两年,AI凭借各方面的成绩证实它能够成为整个互联网的基础设施之一,助力我们的互联网变得更加智能化。
若把2016年的AlphaGo视作现代AI的起始点,那么AI发展的历程实则很短。学术界仍在钻研如何提高AI的算法,各个公司却急于把AI运用到生产环境中。
AI 在感知层大体分为两大类型,一种是计算机视觉,这种已经相对成熟,像是人脸识别、物体检测、运动检测都能够应用于实际场景里。另一种是 NLP,虽说微软、Google 等声称它们的 AI 翻译准确率已然非常高,然而事实上依旧不太实用,并且多轮会话的难题尚未得到解决,Chatbot 依旧很难与人开展正常对话。
总之,真正的通用人工智能AGI距离我们还很遥远,起码目前还找不到任何线索。AI尽管在炒作中显得有些热度过高,但其技术以及应用是实实在在的。
致开发者:2018 年 AI 技术趋势展望
被高估的 2018——深度学习发展并没有想象的快。
值得注意的是,2018年,国内有几家涉及公有云业务的公司,纷纷对架构做出调整,把之前的云计算部门进行升级,使其成为智能云计算部门:
云厂商们把AI当作顶级战略,还将其与云计算放在一起,这是因为AI本身需要强大且专门定制的基础设施,这是云非常适合的一个场景,还因为AI技术存在一定门槛,能作为自身云计算差异化的一个点,总之,这些云厂商借助AI来售卖云服务 。
八、区块链:不确定性
2018年,区块链是极具争议的话题,撇开那些炒作与骗局不谈,能看到这一年区块链技术有很大发展。
具体可分为两方面:
一方面是对公链上一些痛点解决方案进行探索与突破,包括寻找比POW更好的共识机制,提升并发交易性能,解决数据存储和处理问题,实现跨链交易等等。当然,问题远未得到解决。因为利益牵扯过多,所以这一领域没有公认的主流解决方案。
另一方面是联盟链渐渐成熟,联盟链的代表技术是超级账本,一部分早期采用者在探寻联盟链的适用场景,一部分则开展起卖水生意,推出区块链即服务 。
在当下这个时间点,区块链的未来存在着太多的不确定性,这些不确定性使得其无法被预测,因此在这里就不再过多谈论了。
九、物联网与边缘计算:为何发展不起来
物联网在过去几年处于不温不火的状态,好像一直在炒作当中,不过真正有影响力的产品和应用数量比较少。曾经被炒作过一阵的开发板,最终变成了极客的玩具。物联网自身的技术,除了各种通信协议、嵌入式操作系统以及开发框架之外,近两年炒作得最厉害的就是边缘计算了,然而,边缘计算也是炒作的重灾区。
事实上,边缘计算的定义并不明晰,甚至对于边缘是什么都没有达成共识。有人认为终端节点、智能设备属于边缘,有人觉得CDN是边缘,有人称路由器、交换机是边缘,还有人讲未来的5G基站是边缘。
目前边缘计算技术中,仅能看到EdgeX Foundry,然而在这个项目里,当下看不到一项具有代表性的重量级技术,更多的是一些厂商抢占风口的占位举动 。
为什么会出现这种情况呢?实际上很好理解,原因在于物联网是未来一种易于预测的趋势 。
从互联网到移动互联网,这是个不断扩张的进程,终端节点数量大量增多,并且始终保持在线状态,要是把这个逻辑进行延伸,那就是物联网了,此时终端从智能手机转变为任何能够联网的设备。
这是大家都能看到的趋势,正因如此,所有厂商都提前在物联网进行布局,他们试图成为下一个领先者。
互不相让会导致陷入一种局面,那就是三个和尚没水吃的状况。在历史当中,NFC移动支付以及物联网通信协议都经历过这样的情况:
在中国的NFC方面,银联主推miniSD卡的NFC方案,运营商主推带NFC的sim卡,手机厂商则更愿意把NFC功能直接集成至手机中。在国外,美国三大运营商推出了基于NFC的移动支付功能Isis,苹果有自己的NFC钱包,谷歌也有自己的NFC钱包,Android阵营的手机大多把Android Pay功能替换成了自家的支付功能。
在物联网通信协议领域,WiFi、蓝牙、RFID、ZigBee 背后代表着不同利益方,在涵盖工业物联网等行业后,各种私有通信协议多达数十种,直至如今,我们都无法轻易将任意两个支持联网的设备相互连接,由此可见,物联网的发展仍面临诸多挑战,未来之路漫长且艰巨。
智慧城市是物联网的集大成者,可是它的概念自诞生起至今已有数十年,然而我们并未看到一个成功落地的案例。
所以,物联网的发展不会像移动互联网那样一下子就成功,而是借助在共享单车上的应用,通过一个个这样的案例积累起来,才逐渐进入我们的生活。
十、从当下的技术看未来
看了上面的盘点,你会发现云原生是我们当下互联网技术发展的大趋势,真正的云计算也是当下互联网技术发展的大趋势,在这个大趋势之下kaiyun全站网页版登录,会推动不同的领域进行相应的发展。
其中的代表技术,包括机器学习,Kubernetes,Serverless,它们是当前时代技术发展的主要旋律,若你认同此观点,你能够得出这样一个预测:
传统的应用开发会走向真正的云计算,这种云计算以容器、Serverless为代表,随着终端和云更深度地集成,随着物联网发展,随着智能化提升,云和端的界限会变得模糊,我们会更加接近理想中的互联网。
信息技术的革命会让受限于键盘和显示器的计算机获得解放,使其成为我们能与之交谈的对象,成为能与之一道旅行的对象,成为能够抚摸的对象,甚至成为能够穿戴的对象。这些发展会变革我们学习的方式,会变革我们工作的方式,会变革我们娱乐的方式,一句话,会变革我们的生活方式。——尼葛洛庞帝《数字化生存》
《数字化生存》于1996年出版,以前我们对理想的互联网只有凭空想象,如今我们知道了能通过怎样的技术发展路径抵达这个理想。
十一、技术的本质与技术发展的逻辑
技术持续推陈出新,让人目不暇接,然而要是把握住这些技术的本质,就会发觉太阳底下并无新鲜之事。
要是把上面各个领域里的重要技术变革进行提炼,就能够发现其中的一些存在共同点:
当然,这里面会存在一些遗漏,或者有一些是你并不认同的,但是我想要表达的是,这些技术有着一些共同的本质,这些本质是不同领域技术发展的共同逻辑 。
十二、再进一步:是什么在推动软件的发展?
上面我们已经了解了软件的常规发展趋势,然而,怎样去预测软件的颠覆式创新呢?要进行这种预测,我们需要更深入地挖掘软件进步的源头。
软件并非凭空发展,它需要运行在各类硬件之上,软件的进步,同样离不开硬件的支撑。
换个说法,正是硬件持续升级与变革,为软件的发展进步提供了支撑。云计算得以诞生,是因为大型机无法再支撑高并发,这才促使人们转而运用一般硬件以及虚拟化、分布式的软件技术。
软件要实现颠覆式创新,必定是基于硬件的支持,随着现有软件架构对现有硬件能力进行挖掘,而在此情况下,再发生颠覆的可能性已经比较小了。
当然,这并非意味着不存在,像 Docker 的诞生,没有借助特别新的硬件能力,比特币的诞生,同样没有利用特别新的硬件能力,更多的是现有软件发展积累到一定程度后所产生的质变。
但软件创新更多的可能性,则在于硬件的颠覆上。
AWS推出了Aurora数据库,这是一个很好的例子,它基于非易失性存储技术的重大进步而诞生,现在的趋势是,硬件创新体现在软件上的时间会越来越短。
英特尔研发的最新芯片,会被云厂商第一时间订购,英伟达研发的最新芯片,同样会被云厂商第一时间订购,云厂商会充分利用硬件升级带来的性能提升 。
最近,出现了一个新趋势,软件厂商开始驱动硬件进步,谷歌、阿里、华为等都着手自研用于云和终端的芯片 。
若要对软件的发展进行预测,我们就必须去关注硬件可能实现的提升,在此处,我们从软件运行所需的三大资源着手:
对于技术发展的总结基本就到这里了。
选择技术存在风险,对于做To B或者To C的公司而言,若选择了非主流技术,只会演变成长期的技术负债,然而对于面向开发者的云计算公司来说,选错技术几乎注定了之后会衰落,不管是坚持下去还是切换成主流技术,都会因错过最佳时机而步步艰难,这也是近年来新技术受到追捧的一个原因。
这种现象致使技术迭代速度愈发快,开发者若几年不留意新技术,便会产生一种被世界抛弃的错觉,所以每个人都焦虑不安。
我希望借助这篇文章,帮你梳理技术的发展情况,让你清楚正在发生的事情,以及将会发生的事情。一旦了解了这些,想必就不会那么焦虑了。
当然,因为个人能力有限,文章里难免存在错漏的地方,欢迎进行讨论交流。
相关文章
-

kiayun手机版登录打开即玩v1011.玩看我最新关网.中国 1.1 知识与经济关系的历史回顾
-
开·云体育app下载安装 用这3条学习科学原理教学生,能促进知识的深度理解与迁移应用!
-
kiayun手机版登录入口 传感器原理及其应用
-
kiayun手机版登录打开即玩v1011.玩看我最新关网.中国 力学话趣-奇妙的非牛顿流体.doc
-

kiayun手机版登录 在日常生活中传感器会被应用在哪些地方?
-
kiayun手机版登录打开即玩v1011.玩看我最新关网.中国 必看!传感器八大经典应用案例分析
-
kiayun手机版登录.v1008.点进白给你1888.中国 遗传算法应用实例
-
kiayun手机版登录打开即玩v1011.玩看我最新关网.中国 不了解无线传感器?十大无线传感器技术典型案例推荐