改进量子遗传算法在函数寻优中的应用
广西大学 计算机与电子信息学院,位于广西 南宁 530004;浙江海洋学院 数理与信息学院,坐落在浙江 舟山 316000。
标准的量子遗传算法存在容易卡在局部最优点的缺点,并且在处理定义域跨度较大的函数寻优任务时,其优化结果的精确度往往不够理想。通过将量子交叉和模拟退火这两种技术合理地融入量子遗传算法框架内,能够显著降低算法陷入局部最优解的可能性。依据初次优化获得的反馈信息,可以适当地压缩算法的搜索空间范围,以此提升算法在寻优过程中的准确度水平。最终借助繁复双变量式进行验证,所得数据昭示,经由此番改良手段,优化程序的整体效能获得显著增强。
0引言
量子遗传算法是将经典量子计算和传统遗传算法的操作方式相结合而形成的一种新型优化方法,这种算法通过融合两种技术的优势来提升性能。量子遗传算法在种群多样性方面表现优异,能够进行更广泛的全局搜索,并且相比传统遗传算法,它的收敛速度更快,效率更高。
常规量子遗传算法在处理某些极为繁复、性状不佳的优化问题时,难以完全展现其优势,为了增强算法的寻优能力,本研究将模拟冷却过程和量子杂交机制整合进标准量子遗传算法框架,该算法针对量子个体执行量子杂交,促进种群内基因片段的深度交换,同时注入冷却理念,力求防止算法在初期阶段就固定在局部最优解之中完成初次寻优运算步骤,得到对应最佳结果,接着在最佳结果周边的狭窄区域开展二次寻优运算,以此提升算法的寻优准确度。
本文借助若干个结构繁复的二元函数对优化后的量子遗传算法展开验证,实验数据揭示,该算法在全局探索方面展现出显著优势,这一点在文献四中有详细记载。
1量子遗传算法
1.1量子编码
量子遗传算法运用量子编码进行信息表达。量子编码的基础是量子比特,作为信息存储单元[5]。该编码方式借助单个量子比特的叠加形态,将遗传信息具体呈现,其状态由|0>和|1>两种基本态构成。
量子遗传算法里的量子位能够取|0>和|1>之间的任何数值,因此单个量子位的状态可以用公式[6]来描述
|ρ>=λ|0>+μ|1>(1)
量子态的概率幅度λ和μ是两个平方和等于1的复数,对优化种群实施一次测量,|ρ>可能以|λ|2的几率坍缩成|0>状态,也可能以|μ|2的几率坍缩成|1>状态,并且它们需要符合以下表达式要求
|α|2+|β|2=1(2)
在公式二里,量值α的平方代表出现状态零的几率,量值β的平方代表出现状态一的几率,量子系统会自发地变化以便配合评价标准来挑选基因资源。所以,如果一个体系包含m个量子位,那么这个体系就能够同时展现二乘以m种不同的情形。不过,针对量子态四的每一次检测,那个量子位都会确定地变成某个特定的情形。
1.2染色体表示方法
量子遗传算法里,基因由量子比特来象征,这一点在文献中已有记载。基因能够呈现“零”的状态,或者“一”的状态,同样也可能处于这两种状态的中间叠加情形。也就是说,每一个基因位点所承载的不再是一个固定的遗传信息,而是囊括了优化函数所需要的全部优化解集的资讯。所以,针对任意基因位点的任何干预,都可能造成整个种群中所有优化解集信息的变动。本文借助一对平方和为1的复数对(α,β)来描述染色体中的某个量子比特,那么由c个j位基因组成的染色体能够表示为:
公式里,i代表染色体的序列号,n指代染色体现阶段演化的世代次,c表明基因点位数量,第n代第i号的个体染色体以qni来标记;j则说明每个以二进制形式呈现的优化方案里所包含的量子位数目。
2量子遗传算法的改进
2.1量子交叉
标准的量子遗传算法里,不存在量子杂交现象,群体里的基因序列各自孤立,个体之间的构造细节无法得到充分运用。
文献七运用一种称作“全局干扰交换”的交换方法,此方法下所有基因序列均会介入其中,表一简要介绍了本论文中量子交换机制,该机制种群规模为三,基因序列数目为三,每个基因序列的长度是五。
第二个染色体的第二个量子比特记作B(2),通过循环方法执行整体干扰动作。杂交后基因位置的决定方式如下:先以当前基因序号减1的数值,在种群内向下偏移若干格,若偏移格数超出种群染色体总数,则除以当前种群规模,所得余数再减1,即为该基因向下偏移的格数。
表2呈现了实施全局干扰交叉处理后得到的染色体组,例如B(1)—A(2)—C(3)—B(4)—A(5)就是其中一种情况。借助这类方法,种群中每个个体所含的量子位信息都能得到充分运用,在群体进化的后期阶段能够有效维持染色体的多样性,进而提升了算法的整体效能。
2.2模拟退火操作
模拟退火方法借助设定初始温度值与控制实际降温步骤的速度来完成,当温度较高时,算法倾向于接受较差的优化结果,而当温度降低后,算法则更倾向于采纳较好的优化结果,这种处理方式有助于防止算法陷入局部最优状态,模拟退火的搜索策略增强了算法的探索性能与执行效能。
模拟退火方法本质上是一种逐步探寻的步骤,该步骤不断重复“生成新配置,评估适应度kaiyun全站网页版登录,判定能否采纳,决定采纳或放弃”的步骤。其核心步骤包括:首先形成一个新的状况,然后计算该状况的优劣程度,接着判断是否要采用这个新状况,最后做出采纳或舍弃的决定。
(1)初始化,初始温度T,初始解S,每个T值的迭代次数。
(2)对种群完成步骤(3)~(6)。
(3)产生新的解S′。
确定变化量Δ,等于期望值E(S′)减去期望值E(S),其中期望值E(S)就是那个目标函数
(5)若Δ
(6)如果满足终止条件则输出当前解作为最优解,结束循环。
(7)产生新的温度T′=0.95×T,逐步降低T(温度)。
(8)转到步骤(2)。
算法运行期间,为确保其收敛性能,初始退火温度T需尽量高,通常设定为100。
2.3二次寻优计算
2.3.1粗格子点法
先以少量格子点完成初步估算,获得一个近似最优值,接着围绕该近似最优值的小范围区域进行网格加密,并在加密后的点上重新计算最优解,不断重复加密和计算步骤,直至结果达到预定精度。
2.3.2二次寻优计算方式
二次寻优的推算办法跟粗格子点法类似,二次寻优的推算是在初次寻优推算得到最优结果后,在小范围区域再次运用量子遗传算法进行推算,好处在于优化函数的取值范围收窄,最优值分布的区域更加清晰,染色体解的精确度提升。
2.3.3二次寻优计算区域
二次寻优的范围由初次寻优过程中每一代产生的最优解点连缀而成的一系列区间构成。参见图1,以初次寻优确定的全局最优解A为基准中心,测量中心点A到边界点B的间隔距离,以此为基准长度,在该方向上划定二次寻优的界限范围。
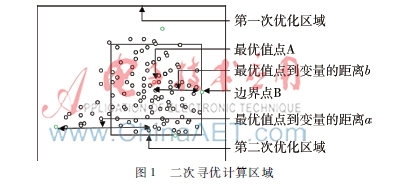
在图1中,如果a
2.4改进算法选择
量子遗传算法的每一次优化都展现出独特的搜索能力。当初次进行优化运算时,如果发现全局最优值产生的世代数非常少,并且搜索成效不理想,通常是因为算法出现了“早熟收敛”现象。所以,在后续的搜索过程中,应当将降温过程加进算法,以此来避免算法的“早熟收敛”。当最优解的迭代次数出现较晚,并且寻优效果不佳时,通常是因为各个染色体之间缺乏联系,结构信息交流不足,导致收敛速度缓慢。在这种情况下,在后续的寻优过程中,需要将量子交叉操作整合到优化算法里,以此来丰富种群的多样性,进而提升算法的寻优能力。通过实施二次寻优计算,能够显著增强算法寻优的精确度。
2.5优化算法流程
改进量子遗传算法(IQGA)流程主要分为以下步骤:
对初始种群Q(t0)执行函数优化过程中的种群初始化步骤,设定初始温度T,每一个优化解集种群的染色体上包含基因位,这些基因位用(αij,βij)来表示,它们的初始维度为(2/2,2/2)。
对初始种群里的每一个体实施一次检测,从而获得那个特定的解P(t0)。
对已确定染色体的优化解P(t0)实施适应度评定,借此明确各解的适应度数值,为后续的遗传筛选步骤提供依据。
(4)记录最优个体和对应的适应度。
评估改进方法能否终止运算过程,若当前改进的解集符合终止运算的标准,就进行步骤十二,若不符合,就继续进行改进操作。
对优化解集种群Q(t)里的每一个体,也就是染色体优化解,实施一次基因位点尺寸的测定,依据这个测定,能够获取对应遗传代数的种群函数优化解集。
(7)对各确定解进行适应度评估。
通过量子旋转门U(t)对每个基因序列实施一次遗传进化处理,当当前代整体适应度数值与上一代适应度数值的差距Δ为负数时,就将当前代最优基因序列认可为新的初始方案,由此形成优化目标函数的新一代最优基因序列集合Q(t+1),当差距Δ为正数时,则按照指数函数exp(-Δ/T)的值来决定是否接受新的初始方案,由此形成优化目标函数的新一代最优基因序列集合Q(t+1)。
(9)对量子染色体进行全干扰的量子交叉操作。
(10)记录最优个体和对应的适应度。
(11)将迭代次数t加1,返回步骤(5)。
选定二次改进的解区域范围,同时将算法的循环次数折半处理,另外对冷却参数进行调整。
(13)根据第一次优化方法,执行步骤(1)~(11)。
3算法性能测试
3.1典型测试函数
(1)多峰函数Shubert[8]
f1函数的参数为x1和x2,其值等于各项之和的最小值,各项的计算方式为余弦函数值,角度参数为(i+1)乘以x1加上i,其中i的取值范围从1到5
∑5i=1icos[(i+1)x2+i]
该函数存在七百六十处局部最小点,其中包括十八个全局最小点,其理论上的全局最小值表现为fmin(x1,x2)等于负一百八十六点七三一。
(2)Goldsten-Price函数[9]
f2函数的两个变量取值范围在负二到二之间,其表达式由两个括号乘积构成,第一个括号内先计算括号内各项,然后平方,接着乘以系数,第二个括号内先计算括号内各项,然后平方,接着乘以系数,最后将两个括号内计算结果相乘得到函数值
此函数在其定义域内只有一个极小值点f2(0,-1)=3。
(3)Sixhump Camel Back函数
f3的值等于括号内第一项乘以平方,加上第二项乘以x,再加上第三项乘以平方,范围是x在负三到三之间,y在负二到二之间
六峰驼背函数存在许多极为接近的局部最小值,难以精确找到全局最小点,其中(-0.0898,0.7126)和(0.0898,-0.7126)是全局最小点,最小值分别为f3(-0.0898,0.7126)=-1.031628和f3(0.0898,-0.7126)=-1.031628。
对比现有方法,本方法计算结果见表3,各函数均运用改良算法执行了20轮运算。量子遗传算法的种群规模确定为40,循环次数定为200,函数每个变量的二进制编码长度为20,初始退火温度调为100℃,退火比例因子为0.95。评估算法优化能力时,从效率和质量两个维度展开分析。
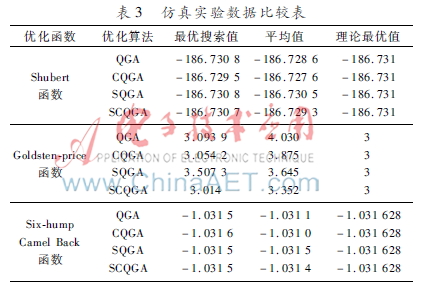
该算法体系包含四个主要版本,分别是基础量子遗传算法,融合量子交叉的版本,引入退火机制的版本,以及结合量子交叉和退火技术的综合版本。
表3数据表明,经过优化的量子遗传算法在效能方面有所增强。对于各类优化目标,该改进方法均展现出更佳的表现。融合量子交叉及退火概念的算法,在面对具有不同属性的优化问题时,依然能维持较强的探索性能。
3.2二次寻优计算测试
为评估二次寻优运算的效果开元棋官方正版下载,选用前文提到的三个代表性函数开展效率验证。将最大遗传代数设定为100代,染色体的规模确定为20位,种群规模维持在40个个体。运算数据与参照数据的具体对比情况见表4。
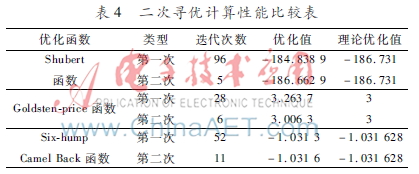
根据表4可知,采用二次寻优方法获得的全局最优结果,比初次计算得到的数值更加贴近理论上的最佳数值,而且其达到稳定状态所需的时间更短。
4结论
本研究在既有量子遗传基础上,引入了全干扰的量子交换及退火步骤开yun体育app官网网页登录入口,增强了量子遗传算法的探索与优化效能,成功规避了常规方法常出现的“早熟收敛”和局部最优陷阱。该研究采用的二次优化计算,显著提升了算法的精确度水平。
然而,这项研究尚存诸多提升空间,例如,二次优化的目标区域选择过于局限,未考虑权重分配,可考虑为每一代的最优结果赋予权重,依据权重来界定二次优化的搜索范围;全局交叉可改为概率式交叉,在维持性能水准的前提下降低交叉频次;并行算法有助于缩短含量子交叉环节的量子遗传算法的执行周期。所以,接下来的任务是在已有成果上,对优化方法进行修正和提升,以便它能更有效地完成目标函数的搜索。
相关文章
-

kiayun手机版登录下载 逆向思维:化危为机的生活哲学
-

kiayun手机版登录打开即玩v1011.速装上线体验.中国 5个“逆向思维”小故事,很短,却改变了无数人的人生轨迹!
-

kia云手机版登录 「夜读」5个逆向思维小故事,让你的人生茅塞顿开
-

kiayun手机版登录打开即玩v1011.玩看我最新关网.中国 8个逆向思维小故事,很短,却改变了很多人!
-
kiayun手机版登录app游戏登录入口.手机端安装.cc 买手机别总盯着跑分 这些传感器同样重要
-
kiayun手机版登录.v1008.点进白给你1888.中国 物理化学Siso是什么
-
kiayun手机版登录入口 物理化学(简明教程)(普通高等教育“十四五”新形态系列教材 高等院校通识课程系列教材 河南省“十
-

kiayun手机版登录入口 2025武汉传感器与应用技术展会:引领智能时代,传感器技术再攀高峰