卷积神经网络及其在图像处理中的应用

一,前言
深度学习方法的一种,针对图像分类和识别专门设计,卷积神经网络是在多层神经网络发展起来的,卷积神经网络(Constitutional Neural Networks, CNN)是这种方法的名称,多层神经网络是它的基础,图像分类和识别是它的应用领域,先来回顾一下多层神经网络。
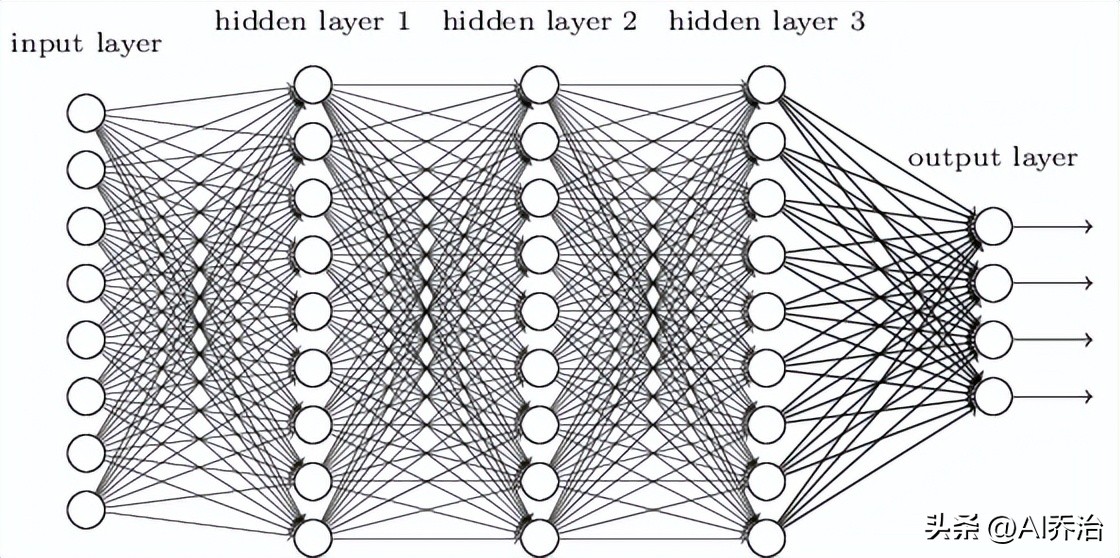
神经网络结构包含起始单元和终结单元,其间设有若干过渡单元。各单元内部均由多个处理节点构成,且相邻单元的节点形成点对点对应关系。常规分析任务中,起始单元用以承载数据集合,单元内部各节点对应集合中的特定属性值。
图像识别任务里,输入单元各自对应图像中的一个像素亮度,或者图像中的一个像素点。不过,这种网络在处理图像时存在若干不足之处,其一,它忽视了图像内部的布局特征,导致识别能力有限;其二,相邻层之间的单元全部关联,参数数量庞大,使得学习过程缓慢。
卷积神经网络能够应对这些挑战,它具备专门为图像识别设计的构造,因而训练过程十分高效,快速的训练周期让构建多层网络成为可能,而多层网络在提升识别精确度方面具有显著作用。
二,卷积神经网络的结构
卷积神经网络包含三个核心要素:局部感受区域,权重大同处理以及降采样处理。
局部感受区域:该图中神经网络的输入部分由单行神经元构成,而在卷积神经网络里,可将输入部分视为神经元以二维网格形式分布的结构
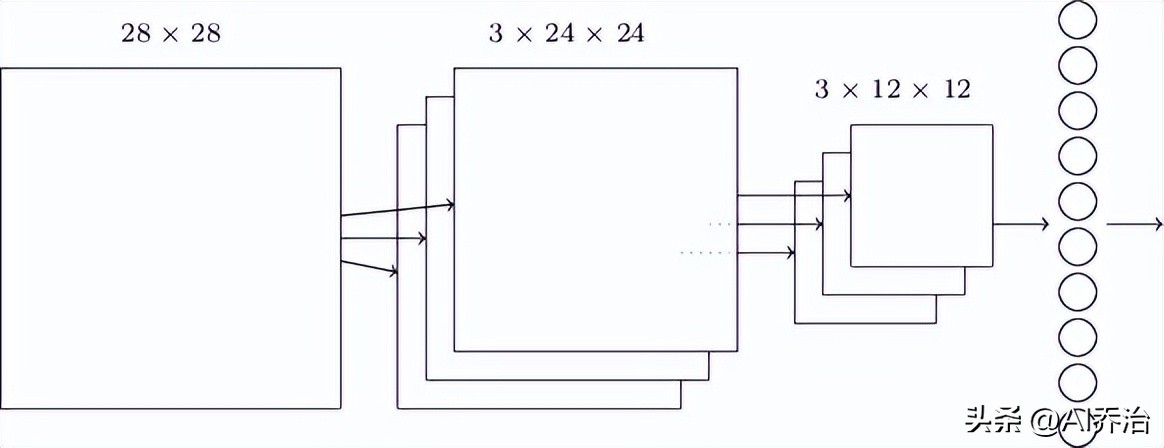
输入层和隐藏层之间,神经元需要建立联系。不过,这种方式和普通神经网络不同,它不会让每个输入神经元都和隐藏神经元相连。相反,它只在图像的一个小范围内部形成连接。比如,对于一个28X28尺寸的图片开yun体育app官网网页登录入口,假设第一个隐藏层的某个神经元,只和输入层中一个5X5的小块区域相接,具体情况如图所示。
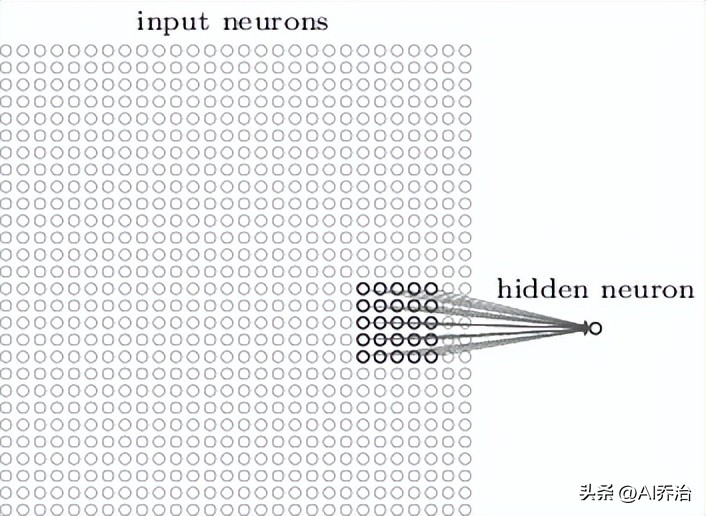
这个5X5的区域称作局部感受区域,此局部感受区域的25个神经元和第一个隐含层的单个神经元相接,每条连接都带有权重值,因此局部感受区域合计有5X5个权重值。当将局部感受区域按照从左至右、从上到下的顺序移动时,会映射到隐含层中不同的神经元,下图分别描绘了第一个隐含层的前两个神经元同输入层之间的连接图景。
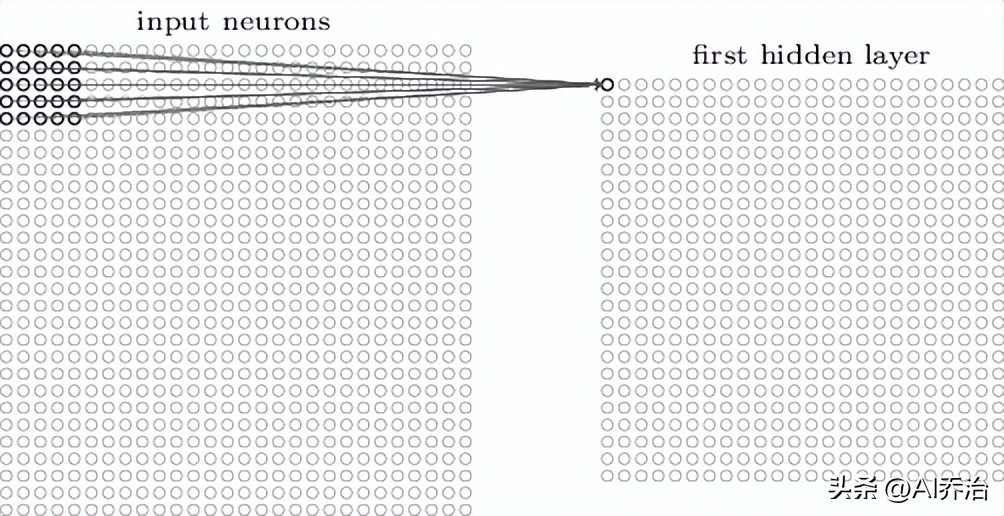
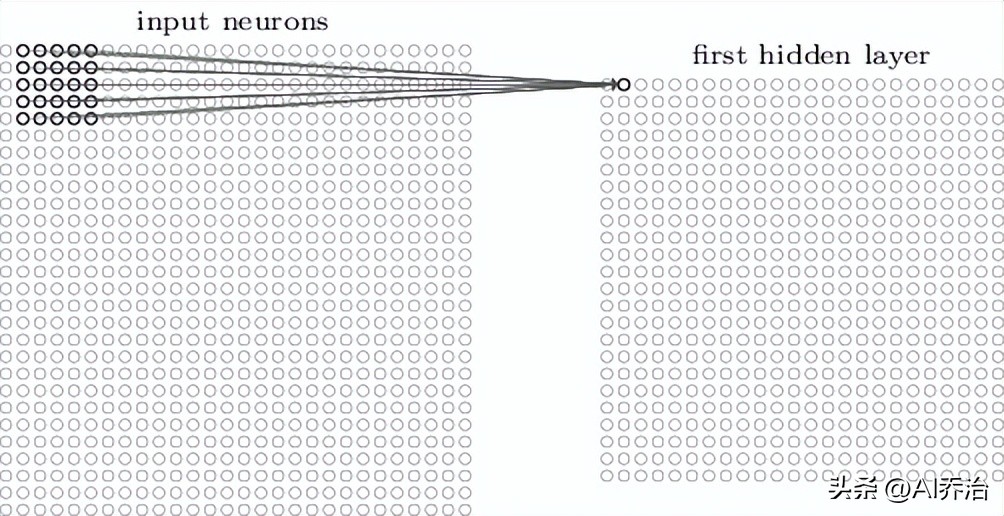
当输入端接收的是宽高均为28的图形时,其局部感受区域设定为5行5列,由此可以推算出首个隐含单元的矩阵规格为24行24列。
共享权重:先前获得的第一隐藏层里全部的24X24个神经元都运用了完全相同的5X5个权重,第二个隐藏层里第n个神经元的输出值等于:
这个是神经元所使用的激活函数,可能是sigmoid函数、thanh函数或rectified linear unit函数这类。这个是感知域之间共用的偏差值。这个是一个5乘以5的共享权重阵列。所以一共有26个参数。这个是在输入层位置的输入激励信号。
这表示第一个隐层里所有神经元都在图像不同点上识别同一特征,所以也将输入层到隐层的这种联系称作特征联系,这种联系里的权值叫做公用权值,其偏置叫做公用偏置。
进行图像识别工作时,往往需要多种特征映射,所以一个完整的卷积层由多个不同的特征映射构成。下面展示了一个包含三个特征映射的情况。
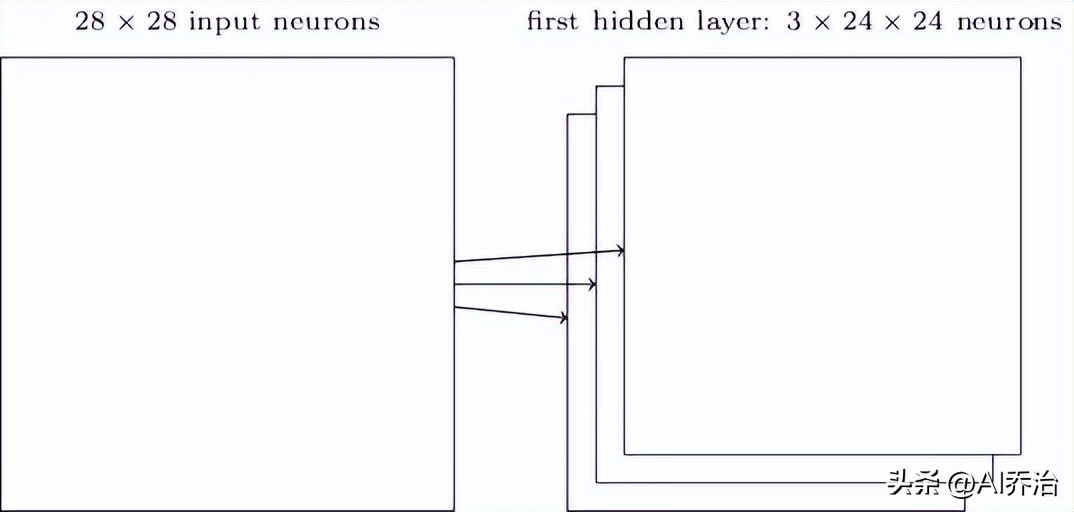
在具体运用中,卷积神经网络或许会运用为数不少,乃至达到数十个的特征映射,以MNIST手写数字识别为例,习得的部分特征包括,

这二十张图分别匹配二十个不同的特征映射(或称为过滤器、核心)。每个特征映射由一个五乘五的图构成,象征局部感知范围内的五乘五组权重值。明亮的像素点象征较小的权重,意味着对应的图像像素影响力较弱。深色的像素点代表较大的权重,表明相应的图像像素将产生更强的作用。能够识别出这些特征映射所呈现的特定空间构造,所以卷积神经网络掌握了部分与构造形态相关的知识来执行识别任务。
池化单元通常跟在卷积单元后面,它的主要功能是压缩卷积单元的输出结果。比如,一个池化单元可能会将前一层中一个2X2范围内的多个单元的信号值进行合并。另一种常见的池化方法是最大池化,这种池化单元会从2X2的输入区域里挑选出最强的信号值作为输出,具体实现方式如图所示。
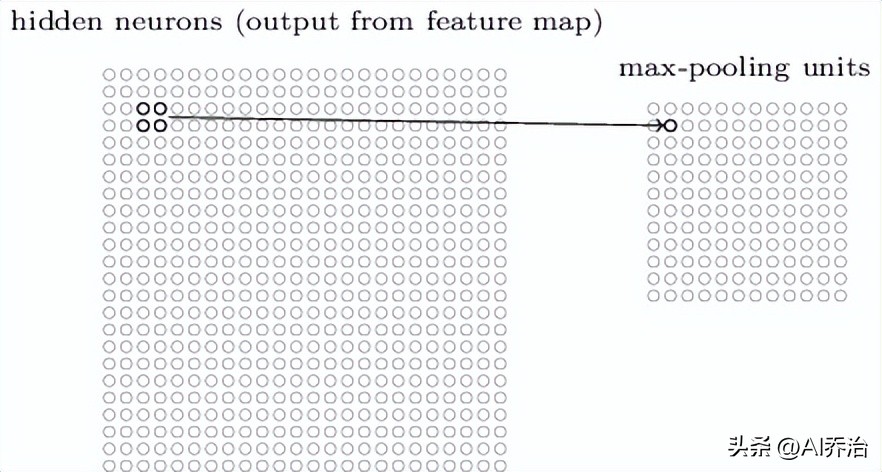
卷积层的结果有24X24个神经元单元,经过池化操作,神经元数量会减少到12X12个单元。每个特征图都要独立进行池化运算,前面提到的卷积层在池化之后的构造如下:
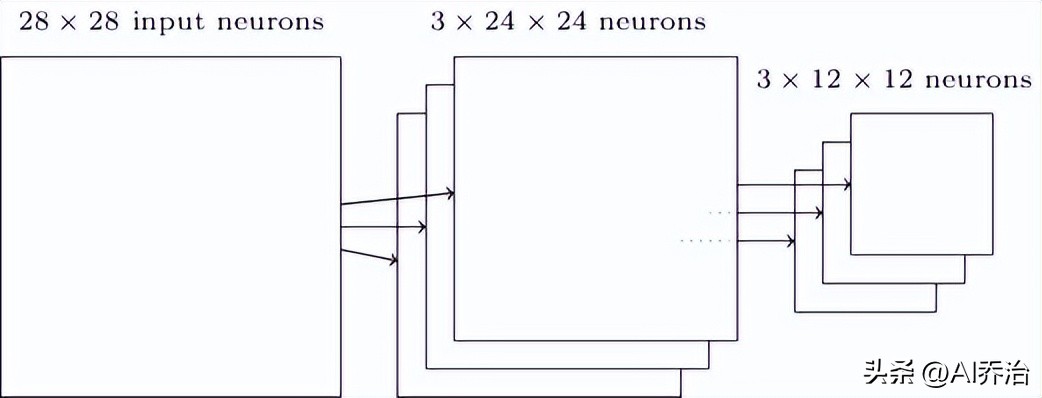
池化方法不止一种,另一种方法是将卷积层中2X2区域里神经元输出的数值先平方求和,再开平方根得到结果。虽然具体操作和Max-pooling不同,但同样能够起到压缩卷积层输出信息的作用。
把那些结构组合起来,再添设一个输出单元,就构成一个完整的卷积神经网络了。在识别手写数字的任务里,那个输出单元有十个处理单元,各自代表0,1,到9这些结果。
网络最底层是一个全联接层级,这个层级的所有神经元,都和上一个最大池化层里的每个神经元相连接。
这种构造在特定情形下适用,常规的卷积网络配置中,有时会在卷积单元和下采样环节后面,增设一个或若干个全连接单元。
三,卷积神经网络的应用
3.1 手写数字识别
Michael Nielsen撰写了一本关于深度学习及卷积神经网络的网络版读物,里面还附带了一个手写数字识别的示范程序,这个程序能够从GitHub上获取。这个程序基于Python和Numpy开发,便于构建各类卷积神经网络以完成手写数字识别任务,同时借助名为Theano的机器学习框架执行反向传播运算和随机梯度下降优化,从而确定卷积神经网络的各项参数值,Theano支持在图形处理器上执行运算,因此能显著减少模型训练所需耗费的时间。CNN的代码在network3.py文件中。
以初次尝试为例,可以试着搭建一个仅含单隐层的神经网络,具体代码如下:
>>> import network3
从名为network3的模块中导入Network这个类
从名为network3的模块中导入ConvPoolLayer类, FullyConnectedLayer类, SoftmaxLayer类
训练数据,验证数据,测试数据由网络三加载共享得到
>>> mini_batch_size = 10
>>> net = Network([
全连接层输入维度为784, 输出维度为100,
Softmax层,输入维度为100,输出维度为10,接着是,小批量大小
网络使用随机梯度下降法,处理训练数据,迭代周期为六十次,每个小批次包含指定数量样本,学习率设定为0.1
validation_data, test_data)这个网络包含784个接收单元,中间层有100个处理单元,末端层有10个输出单元,测试集上的识别精确度高达97.80%。
是否运用卷积神经网络效果会更好吗?可以尝试一种结构,该结构含有一个卷积单元,一个汇聚单元,外加一个全连接单元,具体形态如图所示
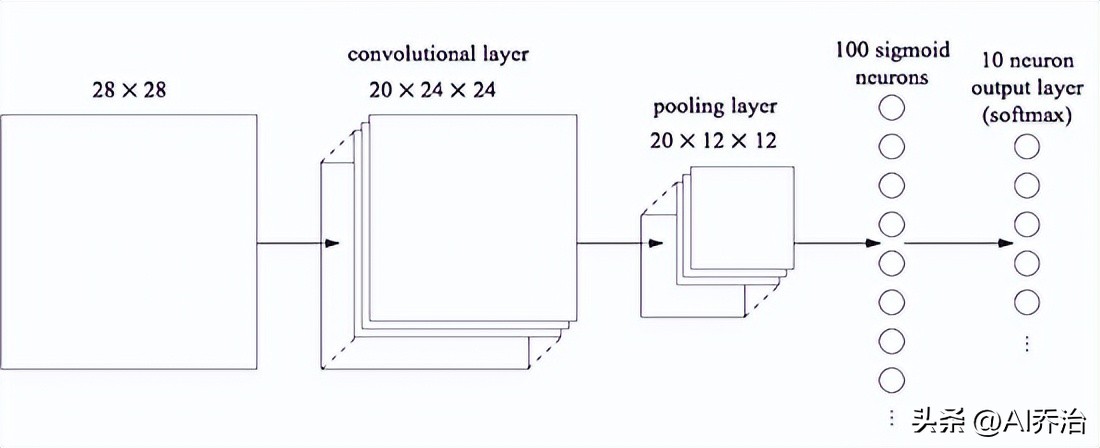
这个结构可以这样认识:卷积层和池化层旨在把握输入图像的局部空间特征,而紧随其后的全连接层则致力于在一个更为宏观的层面上进行学习,它能够整合整个图像所蕴含的更为广泛的整体信息。
>>> net = Network([
图像的形状为 mini_batch_size, 1, 28, 28, 这一层的结构包含了卷积和池化操作,首先进行卷积处理,然后通过池化来降低特征维度
filter_shape=(20, 1, 5, 5),
poolsize=(2, 2)),
全连接层输入维度为20乘以12乘以12,输出维度为100,
SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
>>> net.SGD(training_data, 60, mini_batch_size, 0.1,
validation_data, test_data)这种卷积神经网络构造的检测精确度能够做到98.78%。若希望获得更优的精确度,可以从若干角度进行探讨:
再添加一个或多个卷积-池化层
再添加一个或多个全连接层
可以考虑采用其他激活函数来替换sigmoid函数,例如Rectified Linear Units函数,这种函数相较于sigmoid函数,能够提升训练效率。
扩充训练资料数量。深度学习由于参数众多,必须依赖丰富的训练资料,资料不足时可能难以构建出性能良好的神经网络。常借助特定方法,在既有资料中衍生出大量相似数据以供学习。比如针对图像,可以实施多种变换,包括横向或纵向位移,具体方式有向上移动,向下移动,向左移动,以及向右移动。
采用多个网络进行组合,构建多个具备相同构造的神经网络,参数实施随机设定kaiyun官方网站登录入口,经过训练后在测试阶段通过它们的输出进行投票,以确定最优的分类结果,这种集成的方式并非神经网络的专属技术,其他机器学习算法同样运用此方法来增强算法的稳定性,例如随机森林。
3.2 ImageNet图像分类
Alex Krizhevsky等人在2012年发表的论文《使用深度卷积神经网络对ImageNet的一个子数据集进行分类》中,完成了对ImageNet部分数据集的分类工作。ImageNet总共收录了一千五百万张标注好的高清晰度照片,涵盖了两万两千个不同类别。这些照片是通过互联网收集的,并且经过专业人员完成标记工作。自2010年起,该平台定期举办一项图像识别竞赛,赛事名称为ILSVRC,即ImageNet大规模视觉识别挑战赛。ILSVRC选用了ImageNet里的千种图画,每类图画含约千幅图像。合计有百万二张用于训练,五万张用于验证,十五万张用于测试。所提方案准确率达84.7%,居次方案准确率仅75.8%。
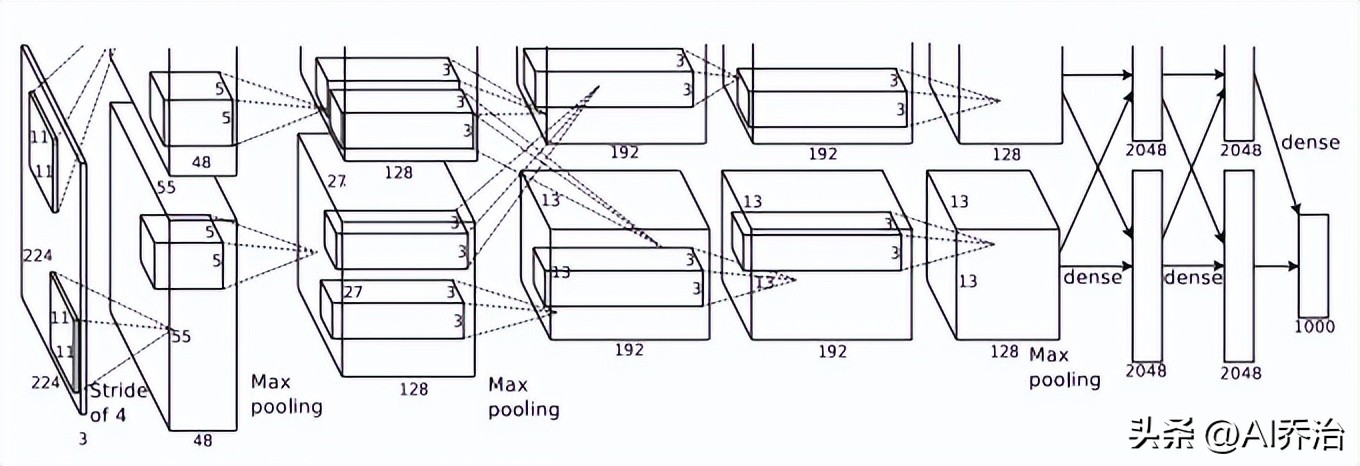
该文档构建了包含七个隐含单元的网络架构,其中前五个单元为卷积单元,部分单元配备了最大池化机制,后两个单元为全连接单元。最终输出单元由一个拥有一千个输出节点的softmax单元构成,每个节点代表一种图像分类标签。
这个神经网络借助GPU来运算,不过单个GPU的存储空间不够用,因此必须配备两个GPU(GTX 580,各自带有3GB显存)才能顺利训练。
这篇文章为了防止模型过拟合,运用了两种策略。第一种是人工创造更多训练样本,比如对现有图像进行平移或水平反转,利用主成分分析调整RGB通道数值等手段。借助这种办法,训练数据总量增加了2048倍。第二种是应用Dropout技术,该技术会随机将隐藏层中一半神经元的输出强制设为0值。通过这种方法可以加快训练速度,也可以使结果更稳定。

输入图像的尺寸为224乘以224乘以3,感知域的规格是11乘以11乘以3。第一层训练完成了96个卷积核,具体形态见上图。其中前48个卷积核是在第一个GPU上训练形成的,后48个卷积核则是在第二个GPU上训练生成的。
3.3 医学图像分割
Adhish Prasoon及其团队在2013年发表的论文《采用三平面卷积神经网络的深度特征学习用于膝关节软骨分割》中,运用卷积神经网络技术实现了对核磁共振图像里膝关节软骨区域的有效划分。常规卷积神经网络仅在平面维度上运作,将其直接推广到立体空间会导致参数数量急剧增加,网络结构也会变得更为繁复,相应地,模型训练过程将耗费更多时间,同时还需要更庞大的数据集支持。然而kaiyun.ccm,如果仅仅采用平面数据,就无法充分提取立体特征信息,这样可能会造成识别精度有所降低。针对这一问题,Adhish提出了一种平衡方法:构建三个分别处理二维平面的卷积神经网络,并将它们的输出结果进行整合。
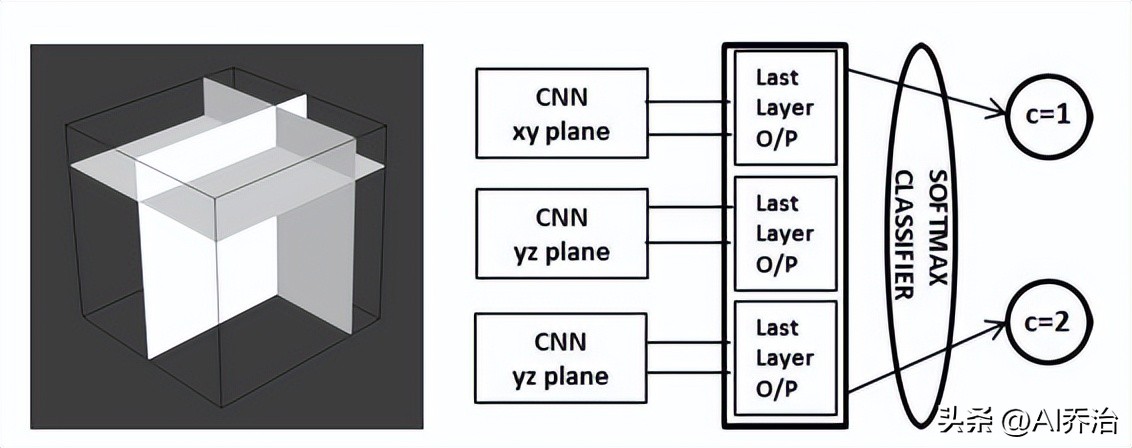
三个二维卷积神经网络各自承担对平面和进行加工的任务,它们的处理结果汇集到一个软最大概率层,由此得出最后的预测值。这项研究使用来自25名患者的图像作为学习资料,从每个立体图像中提取4800个数据点,总共获得了12万个学习数据点。与以往需要人工从立体照片中挑选特征点进行区域划分的技巧不同,这一方法在准确度上有了显著改善,同时使学习过程更加迅速。
3.4 谷歌围棋AlphaGo战胜人类
谷歌的DeepMind小组借助深度卷积网络,在电脑围棋领域实现了关键进展。此前,IBM的深蓝机器凭借惊人的算力,借助全盘搜索策略击败了人类顶尖象棋棋手,然而这种胜利并非源于真正的智能。
围棋的对弈过程比象棋更为繁复,即便借助最先进的电子设备,也无法完全推演每一种可能的着法。围棋的推演是一项异常艰巨的课题,其难度远非国际象棋可比。围棋的终极形态可达三十六一乘方种布局,其规模大约为一百七十位数字,而宇宙内已探测到的原子总数仅八十位。国际象棋的终极形态最多只有十五五乘方种棋局,被称为香农常数,其数值大致为一百四十七位数字。
AlphaGo借助卷积神经网络钻研围棋对弈技巧,最后获得了重大进展。该程序在与欧洲顶尖棋手樊麾的较量中,未受任何让子条件限制,以5比0的比分完胜。研究者还组织AlphaGo与其他围棋人工智能进行比拼,在全部495场对决中仅输掉一场,胜率达到99.8%。它还曾挑战过四个子棋与Crazy Stone、Zen以及Pachi这三款顶尖人工智能的对决,其获胜概率分别为七成七、八成六和九成九,由此可以证明AlphaGo实力超群。
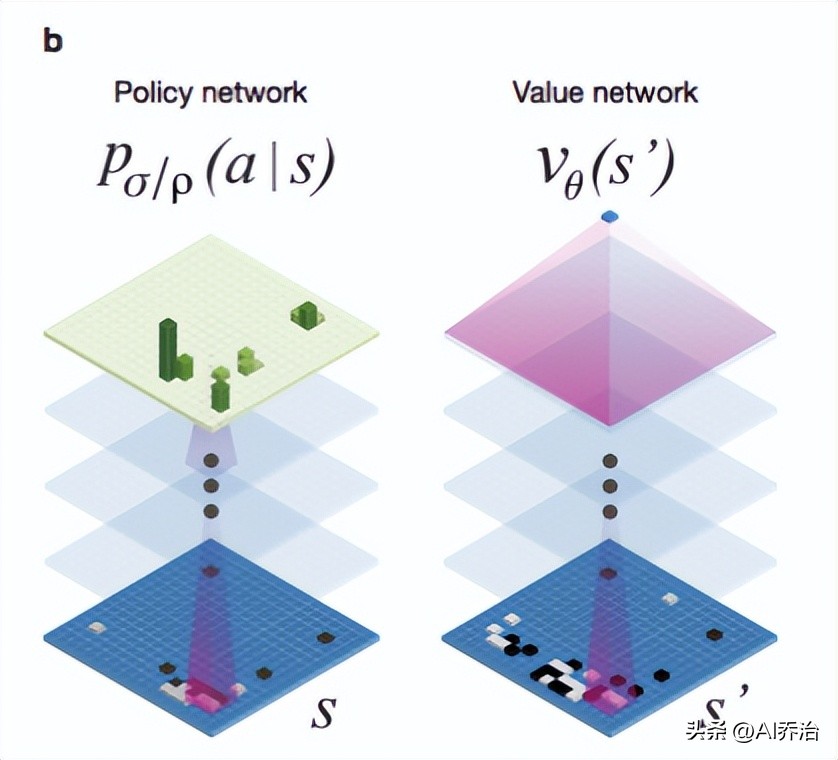
谷歌团队的研究文档里说明,他们借助19X19规格的图形来标示棋盘布局,以此对两种不同的深度学习网络进行培育,这两种网络分别是“策略网络”和“值网络”。它们需要协同筛选出有潜力的着法,舍弃显而易见的劣着,以此将运算负担限定在机器能够处理的程度,这种做法与人类棋手的思路是相通的。
这部分里,“价值函数”的作用是降低探索的层次,人工智能在推演过程中会评估形势,一旦发现明显处于下风,就会舍弃部分选择,不会固执地走完一条路径;而“策略函数”则负责压缩探索的范围,对于眼前的棋局,某些着法是明显要避免的,例如不该轻易让棋子被对方吃掉。借助随机模拟方法,将相关数据置入统计模型,机器便无需对每个环节均等对待,而是能集中精力于具备潜力的落子选择。
为了让众多关注人工智能的朋友能够系统有效地学习并开展论文研究,我们特意汇编了一套人工智能学习资源分享给大家,经过长时间搜集,内容十分丰富。
包括人工智能基础入门的视频和文档,还有AI常用框架实战的视频,涉及计算机视觉、机器学习、图像识别、NLP、OpenCV、YOLO、pytorch、深度学习与神经网络等学习内容,配有课件源码,汇集国内外知名精华资源,同时提供AI热门论文等完整学习材料。
想要获取这些资料,请先关注作者在头条上的账号【AI乔治】,然后回复【666】,就能免费得到这些内容。
每一篇文章探讨的都是深受读者关注且富有意义的内容,倘若我的文字能为你带来启发,恳请你给予点赞、评论和分享,你的鼓励将促使我创作出更优质的作品,在此深表谢意。