应用丰富的“卷积神经网络”技术,怎样实现了图像识别?
“图像识别”这一领域既充满趣味,又极具挑战性。在本文中,我们将借助卷积神经网络这一工具,对“图像识别”这一概念、其应用场景以及相关技术方法进行详细阐述。
什么是“图像识别”?它的作用是什么?
在“机器视觉”这一领域,“图像识别”指的是软件对图像中的人物、地理位置、物体、动作以及文字进行辨识的能力。计算机通过运用“机器视觉技术”kaiyun全站app登录入口,并整合人工智能软件以及摄像头,得以实现图像识别功能。
人类及动物的大脑在识别物体方面显得尤为轻松,然而,对于计算机而言,这一过程却显得格外复杂。人类在目睹一棵树、一辆汽车或是朋友时,能够迅速辨识出所看到的是什么,而这整个过程几乎无需经过有意识的探究与深思。
然而,对于一台计算机而言,辨认出一个物体——无论是时钟、椅子、人,抑或动物——都极为棘手,而寻求这一问题的解决方案亦充满挑战,风险系数颇高。
图片: CS231.github
图像识别技术属于机器学习的范畴,其运作原理主要模仿人类大脑的思维方式。借助这一技术,计算机能够掌握识别图像中的各种视觉对象和元素。通过庞大的数据集和多样化的模式,计算机得以解读图像内容,并以公式形式展现与之相关的标签和分类。
图像识别的普遍应用
图像识别技术被广泛应用于各个领域,其中“个人照片管理”功能尤为普遍,且深受用户喜爱。在处理成千上万张纷繁复杂的照片时,几乎每位用户都希望依照照片的主题进行逐一归类,从而构建出一个井然有序的照片库。
目前kaiyun全站网页版登录,众多照片管理软件正运用“图像识别”技术。它们不仅为用户提供了存储空间,还期望通过“图像自动管理”功能,进一步提升照片搜索体验。软件内置的图像识别编程接口能够依据不同的识别模式对图像进行分类,并按主题进行有序分组。
图像识别技术还广泛应用于——诸如照片及视频分享平台、互动式营销策略、创新性活动策划、社交平台中的面部识别与图像分析,以及处理海量数据时的网络图像分类等多个领域。
图像识别是一项相当困难的任务
图像识别过程颇具挑战性,而采用元数据对非结构化数据进行处理,则是一种有效的实现途径。手动对音乐库和视频库进行专家级别的标注工作看似极其繁重,然而,一个更为艰巨的挑战则是——训练一个无人驾驶车辆的导航系统来辨别道路上的行人及其他交通工具,抑或是使其具备筛选、归类并标注社交媒体上数以千计视频与图片的能力。
解决这一难题的途径之一涉及神经网络的应用。在理论层面,我们能够借助卷积神经网络对图像进行深入分析;然而,从计算资源的角度考量,这一方法代价不菲。以处理一张极为简小的图像(例如,30*30像素)的卷积神经网络为例,它便需调用五十万个参数以及九百个输入。这样的机器功能较为全面,能够应对此类图像处理任务。然而,当图像尺寸增大(例如,达到500*500像素)时开yun体育app官网网页登录入口,所需的参数和输入量也会显著上升。在这种情况下,同一台机器可能无法胜任。
神经网络在图像识别领域的应用中,常常会遇到一个挑战,那就是所谓的“过度拟合”现象。具体来说,当某个模型过于精细地适应了训练集的数据,就可能出现“过度拟合”的情况。这种情况下,模型会拥有过多的参数,从而导致计算成本的大幅上升。此外,当这样的模型在新的数据集上进行训练时,其整体性能往往会受到负面影响。
卷积神经网络
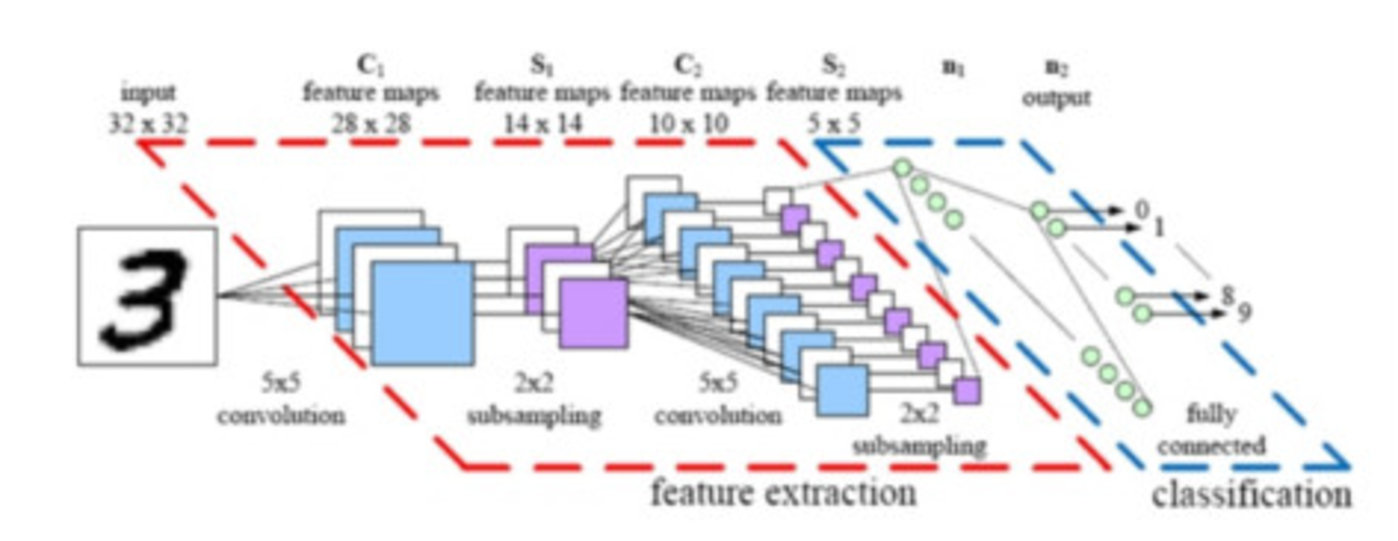
卷积神经网络架构模型(图片: Parse)
在神经网络的结构中,即便是微小的调整,也能使得处理更大图像变得更加便捷。这一改进最终催生了我们熟知的“卷积神经网络”,简称CNNs或ConvNets。
神经网络的广泛适用性是其显著优点之一,然而,在图像处理方面,这一优势却转变成了负担。为此,该卷积神经网络有意识地做出了一个选择:若神经网络旨在专门处理图像,为了实现更可行的解决方案,它不得不放弃一部分普遍适用的特性。
图像之间的邻近性和相似性紧密相连,卷积神经网络正是基于这一特性进行工作的。换句话说,在特定图像中,相邻像素间的关联性要高于分散像素。但在传统神经网络中,每个像素都与所有神经元相连,这会导致计算负担加重,进而影响网络的精确度。
卷积神经网络通过消除这些多余的连接来应对这一问题。在技术层面上,它通过考虑连接的邻近性进行筛选和过滤,从而使得图像处理在计算上变得更加高效可行。
在既定的层级里,卷积神经网络并非将所有输入与神经元一一对接,而是有选择性地限制了这些连接,使得每个神经元仅能接收到该层的一小部分输入。换句话说,网络中的每一个神经元仅负责处理图像中的特定区域。这恰好与大脑皮层神经元的运作机制极为相似,每个神经元仅对视觉感知的一小部分内容产生反应。
“卷积神经网络”的处理流程
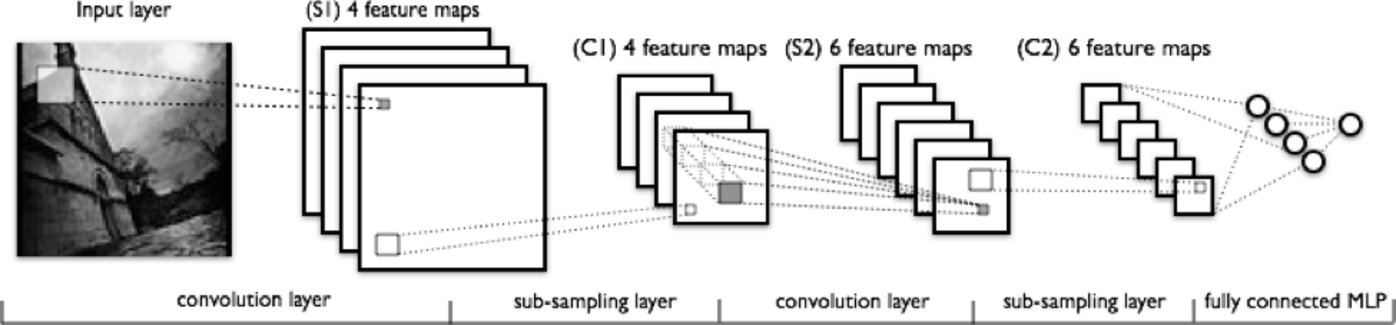
图片: deeplearning4j
从左到右观察上图,你会发现:
图像输入后,将接受特征扫描的处理,而图中那些呈现浅色的矩形区域,便是执行特征扫描作用的滤波器。
“激活映射”层层累积,每一层都对应一个特定的滤波器。随后,较大的矩形区域将进入下一阶段的“下采样”处理。
“激活映射”通过下采样,被不断地压缩。
在“激活映射”堆叠的层上对滤波器进行传递操作,将生成一系列新的“激活映射”,随后这些新生成的“激活映射”将接受下采样的处理。
第二次下采样会压缩新的“激活映射”。
一个全连接的层指定了每个节点的输出为一个标签。
卷积神经网络是如何根据邻近性来筛选出连接的呢?其背后的关键在于引入了两个全新的层级:池化层与卷积层。现在,我们将通过一个具体网络的案例,逐步剖析其筛选过程。
第一步是卷积层,而卷积层本身也包含了几个步骤。
首先,我们把一张照片分解成一系列重叠着的3*3像素块。
随后,我们维持原有的权重不变,让每一个像素块在单一层的神经网络中进行运算。这样做可以把这些像素块串联成一个序列。鉴于我们已将图像细分为众多微小的像素块(本例中为3乘以3的像素块),神经网络的处理过程因而变得更加简便。
随后,这些输出值将被组织成一个数组,数组中的各个数字对应于照片不同区域的具体内容,而坐标轴则分别对应颜色、宽度以及高度。据此,本例中将形成一个3×3×3的数字矩阵。(若涉及视频,这些数字所代表的维度将增至四维。)
接下来的步骤是实施池化层。这一层将处理三维或四维的数组,并将下采样函数与空间维度相结合进行应用。经过这一过程,我们将获得一个仅包含关键图像信息的池化数组。该数组通过剔除非必要的图像部分,仅保留关键部分,从而显著减轻了网络的计算压力,并有效防止了过拟合现象的发生。
经过下采样处理后的数组将成为全连接神经网络的常规输入。鉴于我们已通过池化和卷积显著减小了输入尺寸,目前亟需的是一些普通网络能够处理且能保留关键数据的元素。最终输出的结果将用于评估系统对图像识别的信心程度。
在现实世界中,CNN的运作机制相当复杂,它包括众多隐藏层、池化层以及卷积层。而且,一个完整的CNN往往还拥有数千个标签。
如何建立一个卷积神经网络?
构建一个卷积神经网络成本高昂且过程漫长。为此,科技公司推出了API,旨在使各类组织即便没有机器学习或计算机视觉领域的专业人才,也能实现这一目标。
Google Cloud Vision
谷歌推出的“Google Cloud Vision”是一款视觉识别API。该API的构建依托于开源的TensorFlow框架,并采用REST API技术。它整合了丰富的标签数据集,具备人脸和物体检测功能。
IBM Watson视觉识别
IBM Watson视觉识别系统是Watson开发云平台的一个组成部分,该系统内置了丰富的类别库,能够依据用户提供的图像数据进行自定义类别的训练。此外,它还具备众多高级功能,例如不适宜内容检测以及光学字符识别检测。
Clarif.ai
Clarif.ai是一款新兴的图像识别服务端,同样采用了REST API技术。该服务端具备可调节算法的模块,这些模块可根据用户需求,将算法调整至特定领域,例如美食、旅行或是婚礼等主题。
尽管该API适用于大多数场景,但针对特定任务定制一个专属的解决方案会更为理想。值得庆幸的是,目前众多数据集的可用性使得开发者和数据科学家能够集中精力在模型训练、网络优化及计算难题上,从而使得他们的工作负担有所减轻。
卷积神经网络的一个有趣应用
给无声电影自动配音
为了与无声视频相匹配,系统需在视频内容中生成相应的声音。该系统通过上千个视频样本进行学习,这些样本展示了鼓棒敲击各种材质时产生的不同声响。借助深度学习模型,系统将视频中的每一帧与预先存储的声音库进行匹配,最终挑选出与视频画面最为契合的声音。
随后,该系统将通过一台测试设备接受检验,而这台设备在辨别真声与假声(即合成声音)方面与人类使用的设备极为相似。不得不提的是,这实乃一种独特而引人入胜的卷积神经网络与LSTM递归神经网络的应用。下面,请观看这段视频。