开·云app体育登录入口 应用丰富的“卷积神经网络”技术,怎样实现了图像识别?
“图像识别”属于一个极具趣味性、却颇为具备挑战性的研究领域 ,本文会采用卷积神经网络去深入讲解“图像识别”的概念、应用以及技术方法 。
什么是“图像识别”?它的作用是什么?
基于“机器视觉”的视角而论,“图像识别”乃是软件针对图像里所呈现的人物、地理位置、物体、动作以及文字予以识别的能力。计算机能够运用“机器视觉技术”,并辅之以人工智能软件以及一个摄像头,达成图像识别。
对于人类大脑而言,识别物体是极为简单的,再对于其他动物大脑来讲,识别物体也是十分容易的;然而,针对计算机而言,如此这般的识别却是颇为困难的。人类在看到一棵树时,能够即刻说出所看到的事物,在看到一辆车的时候,也能够马上说出看到的是什么,或者当看到一个朋友时,同样能够迅速说出看到的是谁,根本无需进行有意识地研究,根本不必开展思考活动。
然而,对于一台计算机来讲,去识别一个物体,这物体有可能是一个时钟,也有可能是一张椅子,又或者是一个人,甚至是一只动物,这是一个非常困难的问题,并且,去寻找这个问题的解决办法,具有相当高的风险。
图片: CS231.github
机器学习方法里有一种是图像识别,它专门对人类大脑运行方式进行模仿。借助图像识别,计算机能学会识别图像里的视觉对象以及视觉元素。利用庞大的数据集与各种新兴的模式,计算机可以理解图像,还能用公式表达出相关的标签和类别。
图像识别的普遍应用
利用图像识别能进行极为广泛的应用,其中“个人照片管理”这种应用最为常见,另外它也是备受欢迎的应用。面对成数千数之多复杂多样又杂乱的照片,基本上每个人都期望依据照片所体现的主题将它们逐个进行分类,进而整理成具有条理、有序排列的照片集 。
如今,那些被用于照片管理的应用程序,正在运用“图像识别”这项技术,这些程序除了给用户供给照片的存储空间外,还但愿借由“图像自动管理”,进而为人们给予更优的照片搜索功能,应用程序里的图像识别编程接口,能够依据各异的识别模式把图像予以分类,而且将它们依照主题逐个分组 。
图像识别的别的应用涵盖,照片网站,视频网站,互动式营销,富有创意的活动,社交网络里的面部识别与图像识别,还有庞大的数据集背景下的网络图像归类等 。
图像识别是一项相当困难的任务
识别图像并非易事,实现它的一个好法子,是将元数据用于非结构化数据。雇人类专家手动标记音乐曲目库与视频库,看似是极为艰辛的任务,然而,更无法达成的任务是,教会无人驾驶汽车的导航系统分辨道路上的行人和其他车辆,或是让导航系统筛查、归类并标记社交媒体上数以千计的视频与照片。
办法之一是借助神经网络解决这一问题,理论上,我们能够运用卷积神经网络剖析图像,然而从计算角度来讲,实际上 costs 就会很高,比如对于一个处理很小图像(假定为 30*30 像素)的卷积神经网络,即便如此依然需要五十万的参数以及 900 个输入。一款具备相对较为强大功能的机器,能够对这样的图像予以处理,然而,一旦图像尺寸变得愈发大了起来(诸如处理一幅尺寸为500*500像素的图像),那么,与之相应地,参数以及输入的数量将会攀升至极为高的水准,同一台机器便不一定能够达成对此的处理了。
把神经网络运用到图像识别里出现的另外一个问题是,过度拟合。简单讲,当一个模型把自身调整得跟训练数据特别接近的时候kiayun手机版登录下载,就会出现过度拟合。过度拟合会致使更多的参数,进而增添计算成本,并且模型在新数据上的训练会让总体性能有损失 。
卷积神经网络
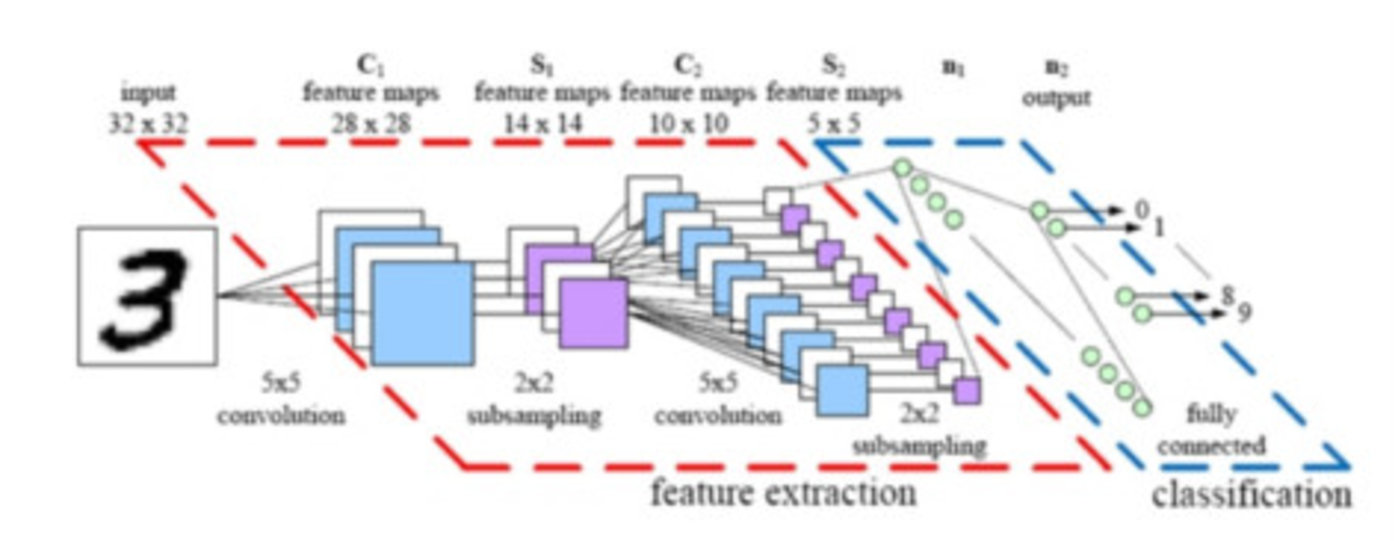
卷积神经网络架构模型(图片: Parse)
关于神经网络结构,存在这么一种情况,即一个相对而言算得上简单的改变,能够达成让更大尺寸的图像在管理方面变得更加容易的效果。如此一来,所产生的成果便是我们所提及的“卷积神经网络”(也就是CNNs或者ConvNets)。
神经网络具备普适性,这是它的优势之一,然此优势在处理图像时,却转变成了一种负担,这个卷积神经网络特意做了一番权衡,要是一个神经网络专门用于图像处理,那么为了达成更为可行的解决方案,就不得不牺牲其一部分普遍适用的特性。
任意一张图像kiayun手机版登录打开即玩v1011.速装上线体验.中国,其邻近性跟相似性存在紧密关联,卷积神经网络正好借助了这种关联。这表明,在一幅给定图像里,两个相邻的像素相较于两个分开的像素,相关性更强。然而,在一个常规神经网络中,所有像素都与所有神经元相连接。如此一来,额外的计算负担会让网络准确率降低。
在卷积神经网络里,是通过将那些没必要有的连接去除掉,以此来把这个问题给解决掉的。从技术层面去看,卷积神经网络依据邻近程度,对连接展开筛选还有过滤,这样一来,使得图像处理在计算方面变得更具可行性 。
在一个给定的层当中,卷积神经网络并非是简单地把所有输入跟所有神经元相连接,而是有意识地去限制这些连接,如此一来,任意一个神经元仅仅会接收来自该层的一小部分输入。也就是说,网络的每个神经元仅仅负责处理图像的某一部分。(这跟我们大脑皮层神经元的运行方式极为相似——大脑中的每个神经元仅会对你视觉感受的一小部分作出响应。)。
“卷积神经网络”的处理流程
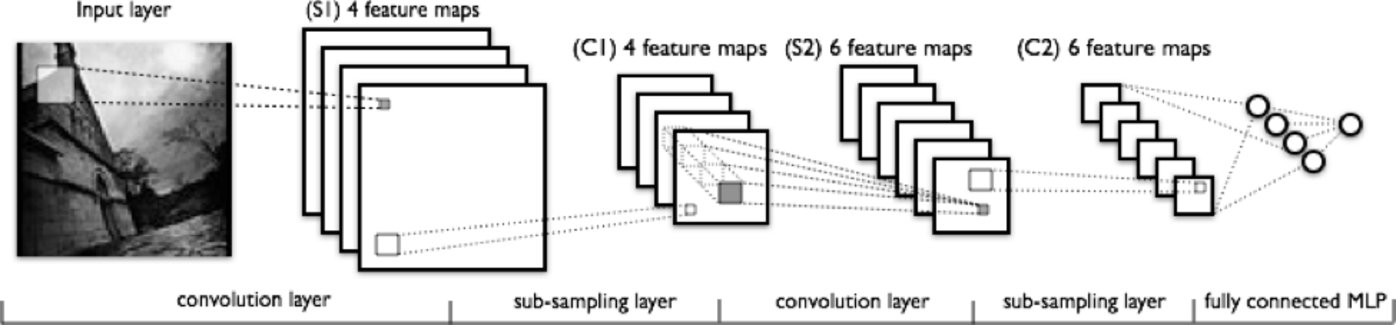
图片: deeplearning4j
从左到右观察上图,你会发现:
将会对输入的图像做特征扫描处理,图里浅色的矩形是用于进行特征扫描的滤波器,是这样的情况 。
一层一层相互叠加着的是“激活映射”,一个滤波器对应着一个“激活映射”。在下一批将会对较大的矩形进行“下采样”。
“激活映射”通过下采样,被不断地压缩。
在“激活映射”堆叠的层上传递滤波器,会产生一组新的“激活映射”,这组新的“激活映射”将会首先遭遇下采样。
第二次下采样会压缩新的“激活映射”。
一个全连接的层指定了每个节点的输出为一个标签。
怎样通过邻近程度让一个卷积神经网络去过滤连接呢,其中的秘密处于两个新的层,池化层以及卷积层,接下来,我们会利用一个网络的示例,将其过滤的流程进行分解 。
第一步是卷积层,而卷积层本身也包含了几个步骤。
首先,我们把一张照片分解成一系列重叠着的3*3像素块。
之后,我们在权重保持不变的情形下,让各个像素块在一个简单的单层神经网络中运行。如此这般做下去kiayun手机版登录app游戏登录入口.手机端安装.cc,这一系列像素块会变成一个数组。由于我们已把图片分解成很小的像素块(在本案例当中是3*3的像素块),故而其神经网络的操作就变得简单许多了。
之后,输出值会被排列于一个数组内,数组里的数字各自代表照片各个区域的内容,坐标轴分别是颜色、宽度以及高度,所以,在此案例里会有一个3*3*3的数字来表示。(要是为视频,那么数字表示便会变为四维的。)。
下一步是池化层,它会对这些三维或者四维的数组进行池化,还会将下采样函数与空间维度结合运用,经过这样的操作,会得到一个仅含有重要图像部分的池化数组,由于这个数组删减了不必要的图像部分,仅保留较重要的部分,故网络的计算负担被降至最低,同时避免了过度拟合的问题。
常规全连接神经网络的输入会是这个经过下采样处理的数组,因为前面已经借由池化与卷积大幅缩减了输入尺寸,此时需要一些普通网络能处理的、可保留最重要数据的东西,最后一步输出会被用于系统判断其对图像有多少把握 。
以现实生活而言,CNN的流程繁杂多样,涵盖诸多隐藏层,包含众多池化层,还有不少卷积层。除此以外(注:这里为了符合要求,表述稍弱化了与上文的衔接),真正的CNN常常含有成千上万的标签 。
如何建立一个卷积神经网络?
搞一个CNN出来是极为费钱并且耗费时间的。被科技公司所研发的API,有着这样的目的,那就是使得组织能够在没有内部机器学习方面的专家或者计算机视觉方面的专家的情形下,同样达成所想达成的目的。
Google Cloud Vision
将谷歌视觉识别 API 称作“Google Cloud Vision”,其构建依托开源 TensorFlow 框架,采用之是一个 REST API,它涵盖全面标签数据集,可检测人脸及物体 。
IBM Watson视觉识别
“华生视觉识别”属于“华生开发云”的一部分,它拥有一个庞大的内置类别集合,它能够依据你所提供的图像来对自定义的类别开展训练,它同样支持诸多较为高端的功能,像是NSFW检测,OCR检测 。
Clarif.ai
Clarif.ai是个新兴的图像识别服务器,它用的同样是REST API,它有着能调整算法的模块,这些模块能把算法调节到特定主题上,诸如美食主题、旅行主题或者婚礼主题 。
上面的 API 适用于一般情形,然而,最好针对单个任务定制专门解决方案。幸运的是,现在众多数据集能让开发人员以及数据科学家专注于训练模型,处理好网络优化与计算方面问题,如此他们的工作会变得相对轻松些。
卷积神经网络的一个有趣应用
给无声电影自动配音
为了匹配无声视频,系统得在视频里合成声音,此系统借助上千个视频训练,这些视频中有鼓棒敲击不同表面发出的各异声音,一个深度学习模型把视频各帧与预先记录的声音库关联,挑选出与视频场景最适配的声音。
而后,此系统会经由一个测试装置加以评估,该测试装置和人类用于判别真声或者假声(合成声音)的装置非常相像。不得不讲,这是一个极为特别、有意思的卷积神经网络以及LSTM递归神经网络应用。请观看下方的视频:
相关文章
-

kiayun手机版登录.v1008.点进白给你1888.中国 9个逆向思维小故事,幽默精辟!
-

开·云体育app下载安装 逆向思维小故事:探索生活中的新解决方式
-
开·云app体育登录入口 应用丰富的“卷积神经网络”技术,怎样实现了图像识别?
-

kiayun手机版登录入口 电磁炮,请问电磁炮的工作原理是什么它与其它常规武器相比具有什么优势
-
kiayun手机版登录打开即玩v1011.速装上线体验.中国 8个逆向思维小故事,幽默精辟
-

kiayun手机版登录 电磁轨道炮的原理和应用前景
-
云手机网页版 以火灭火 逆向思维故事之二
-
kiayun手机版登录打开即玩v1011.速装上线体验.中国 伯努利原理和飞机升力,这3个要点你知道吗?