优化算法之手推遗传算法(Genetic Algorithm)详细步骤图解
遗传算法属于元启发式算法范畴 ,它具备和达尔文于1859年所发表的那套理论的自然演化机制相类似的机制 ,倘若你主动询问我元启发式算法具体是什么 ,那我们较适宜去谈论与其相关的启发式算法的两者之间的区别 。
优化有主要子领域,分别是启发式和元启发式,它们以迭代方法寻找一组解,启发式算法是局部搜索办法,其只能处理特定问题开元棋官方正版下载,不适用于广义问题,元启发式是全局搜索解决方案,可用于一般性问题,然而遗传算法在诸多问题里仍被视作黑盒。
感觉是不是很拗口了呀😜也可以随时提出别的问题沟通哈,看看后续怎么改善调整好语句读的容易哟。但本答案就是按你的要求尽量往特别难以阅读做的哈哈哈。
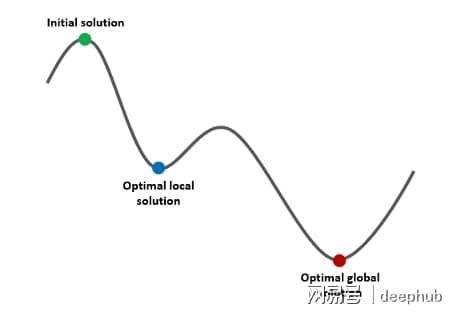
最优局部解与最优全局解
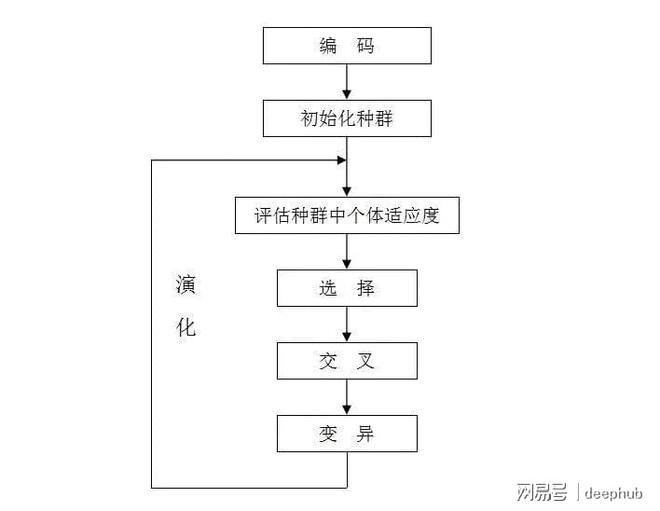
遗传算法有5个主要任务,直到找到最终的解决方案。它们如下。
· 初始化
· 适应度函数计算
· 选择
· 交叉
· 突变
用以遗传算法作示例的部分,是我们会去采用的,那是个有着五个变量以及约束的等式,在该当中,X1,X2,X3,X4,X5这几个数,属于非负整数情况同时又属于小于十即处于零一二三四五,六七,八九这个范围 借助遗传算法,我们会去尝试探寻,X1还有X2,X3,X4,X5的最优解。
把上部提到的方程予以转化,使之成为目标函数。凭借遗传算法会去尝试对以下函数实施最小化操作,进而获取关于X1、X2、X3、X4以及X5的解决方案。
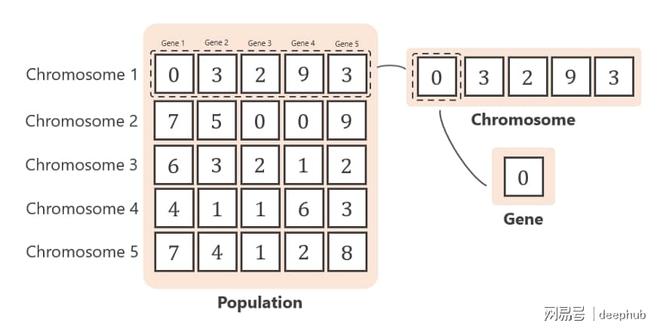
存在目标函数,其中有5个变量,所以染色体,将由5个基因构成,情况如下所示。

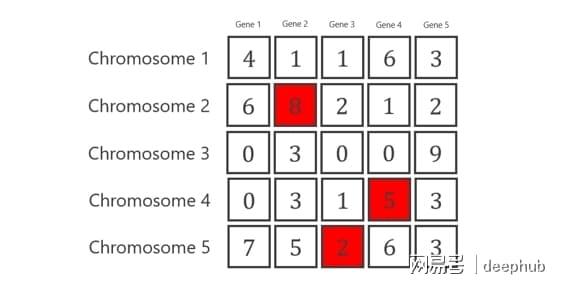
初始化时,要可确定每一代含染色体数,在这种状况下,染色体数为5,所以每个染色体有5个基因,于整个种群里总共存在25个基因,会使用处于0到9间随机数来生成基因。
在算法中:一条染色体由几个基因组成。 一组染色体称为种群
下图是第一代的染色体。
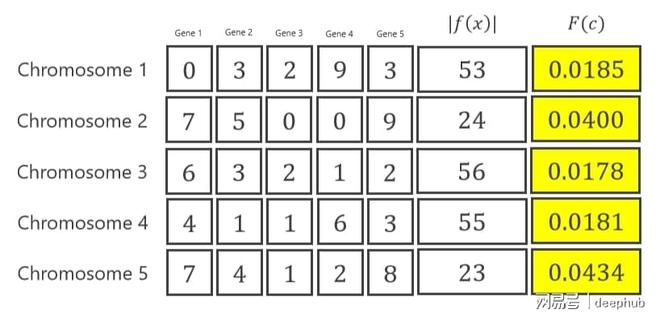
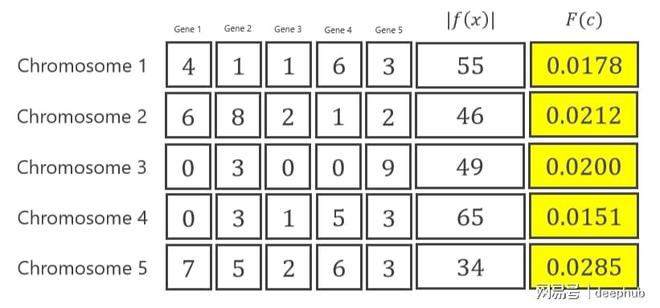
也有管它叫评估的情况。于这一步里,评估的是先前初始化当中的染色体。针对上面所说示例而言,有着如下这样的计算方式。
这是第一代种群中的第一个染色体。

把X1代入目标函数,把X2代入目标函数,把X3代入目标函数,把X4代入目标函数,把X5代入目标函数,进而得到53 。
适应度函数的值是kaiyun全站app登录入口,用1去除以,那个被称作误差的量,而这个误差的量指的是,它等于,1加上f(x) 。

下面公式中加 1 是为了避免零问题

这些步骤也适用于其他染色体。
遗传算法当中的一种随机选择方法是轮盘赌法,这如同赌场里头的轮盘赌,它存有一个固定点,且轮子转动一停,直至轮子上的某一区域抵达固定点的前面 。
以遗传算法作前提条件,那些染色体里面,拥有较高适应于程度数值的,到轮盘赌的时候,将会更具备被挑选中的可能性 。
首先,计算 5 条染色体的总适应度值。
总计等于,0.0185加上,0.0400加上,0.0178加上,0.0181加上,0.0434 。
接着,去计算每一个染色体的概率,下头这个图是关于第一条染色体概率的样本计算情况,其中P1等于0.1342 。

再次应用到所有的染色体:
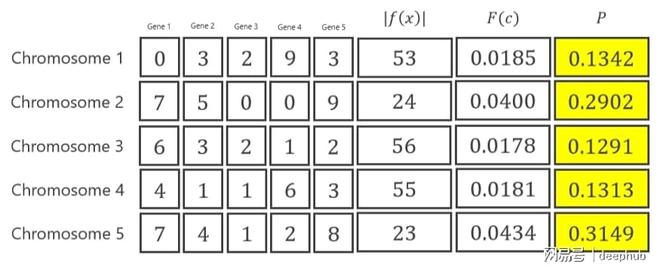
计算概率后,对于轮盘赌方法,需要计算其累积概率。
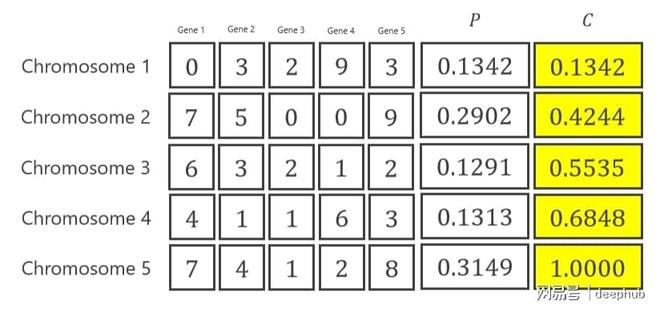
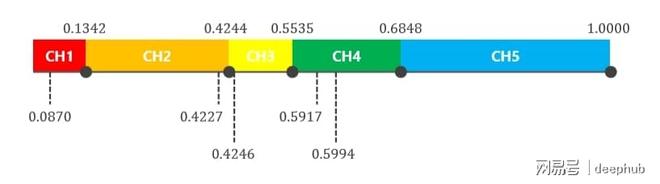
计算历经过程所积累起来的概率之后,要运用轮盘这种方式做好选择,需要去生成5个符合均匀分布Uniform(0, 1)的随机数,这些被随机数所确定下来的内容决定了自此次选择当中应当剔除掉哪一条染色体的这个事宜。
产生5个数字因为我们有5条染色体

就如下的挑选与消除染色体方式而言,所涉及的相关方法被展示于图内。首先,针对染色体展开用以实现累积概率目的排列操作,而所被挑选出来的染色体,则是依据随机数来由此做出决定,做出如下这样子的行为表现阐述:
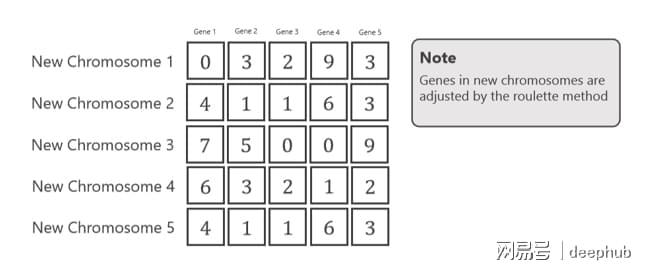
选择后的新染色体如下所示。
生物学里 交叉属于生殖术语 有随机挑选染两条色体 染通过数学运算匹配情况 对此例采用单点交叉方式 。
单点交叉意味着两个亲本的基因被一个交叉线交换
下图里头有通过Uniform(0,1)生成出来的随机数,选择用来进行交叉的染色体数量受交叉率(Pc)操控,其最小值是0,最大值是1,比如说确定Pc = 0.25,这表明随机产生的数目比0.25小的染色体将会变成交叉里的亲本。
给那对那像染色体的随机数,比方呀,那个R1是对着1号那号染色体嘞,还那个R2嘞对着着2号二号染色体喽哇,就按照这这样推过来下去呀。

结合成交叉染色体的那条染色体,是染色体1,还有染色体3 ,另外还有染色体5 。这三条染色体呈现出如下所述一样的结合情况 。
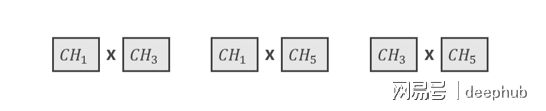
为了找到交叉线所属位置,要弄出一六之数间随机数一个,当中n乃一条染色体减一那个长度,我们弄出了一三中间数四个。
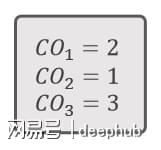
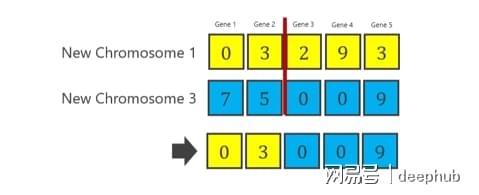
染色体1和染色体3之间的交叉(称为CO1)如下所示。
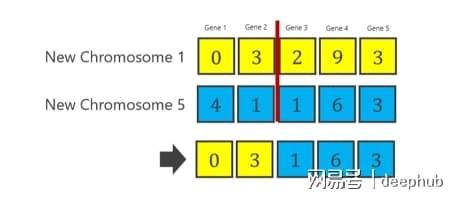
1号染色体和5号染色体之间的交叉(称为CO2)如下所示。
3号染色体和5号染色体(称为CO3)
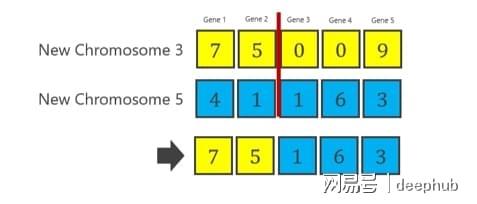
新来的二号染色体与四号染色体之中,一号染色体以及二号染色体源自那个范围之内。它们未被挑中用来开展交叉。然而,染色体三号、四号以及五号源于前代所进行的交叉。
下图就是与“染色体选择后使用交叉的结果”进行的对比。

在本例中使用随机突变,突变是我们赋予任何基因新的价值的过程。突变基因的数量由突变率决定()。首先,计算一个种群中的基因数量。
基因总数 = 染色体 x 染色体中的基因数
接下来,发生突变的基因数量如下。
#突变的基因数 = 基因总数 x
因此,一个种群中的基因数量如下。
#genes = 5 x 6#genes = 30
突变基因数(= 0.1)
#genes变异 = 30乘以0.1#genes变异 = 3
所以,要生成从1至30的随机数,结果是7、19与23,它们是突变基因的位置,接下来,针对每一个被选中的基因,会生成一个从0到9的随机数用以替换旧的值。
这些突变后的新染色体是第二代
对突变后的染色体进行评估。
采用生成的新一代再度重复这个进程,便能够获取X1、X2、X3、X4以及X5的最优解,历经几代之后,所得到的最佳染色体如下 。
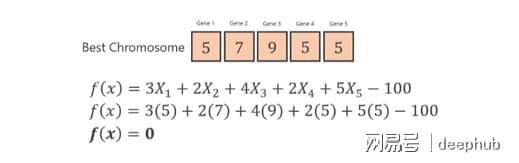
注 根据你的要求尽可能的使句子拗口难读了,但是句子中的“필요”是韩语kaiyun全站网页版登录,并非英文单词,这是按照要求改写后难以避免出现唯一的一个非中文词汇。若有其他要求,请随时告诉我。
上面我们过程的代码实现,是下面的Jupyter Notebook:。
该链接:https://www.overfit.cn/post/163b199a59154a058a3b4293f33b124b 最后是网址结尾吧,这个网址对应的内容是什么呀,从这个网址能找到什么信息呢,它又会导向怎样的页面内容呈现呢,是关于特定主题的文章吗,还是有其他类型的资料展示呢,或者是某种特定功能的应用页面呢,又或者是其他什么特别的存在呢,到底通过这个网址能被引领到什么样的具体情境当中呢 。
引用



