基于遗传算法的特征选择:通过自然选择过程确定最优特征集
遗传算法是借助自然选择原理来处理优化问题的方法。 本文旨在说明如何运用遗传算法执行特征筛选。
scikit-learn 包含了众多广为人知的特征筛选技术,然而特征筛选的技术远不止这些,并且远远超出了 scikit-learn 所提供的范围。特征筛选是机器学习的重要环节。但是鉴于技术的迅猛发展,当前正处于信息爆炸时期,存在大量可供使用的数据,因此常常会出现特征冗余的情况。许多特征都是重复的。 它们会为模型增加噪音,并使模型解释出现问题。
我们需要找出哪些特性同该问题有关联。 我们追求的目标是获得优质特性。
遗传算法
本篇文章使用了“sklearn-genetic”包:
这个软件包能够与现存的sklearn模型配合使用,并且针对遗传算法中的特征挑选功能提供了丰富的选项。
本文运用遗传算法实施特征筛选开元棋官方正版下载,遗传算法同样能执行超参数调节,这些环节十分基础且普适,故可应用于众多不同范畴。
特征选择
挑选属性是个NP难题,任何NP类问题都能用多项式时间算法处理。提供一组属性,最佳方案是这些属性的全体或部分组合。这种策略属于离散挑选。在属性组合排列场景中,找出最优属性组合的代价相当大。
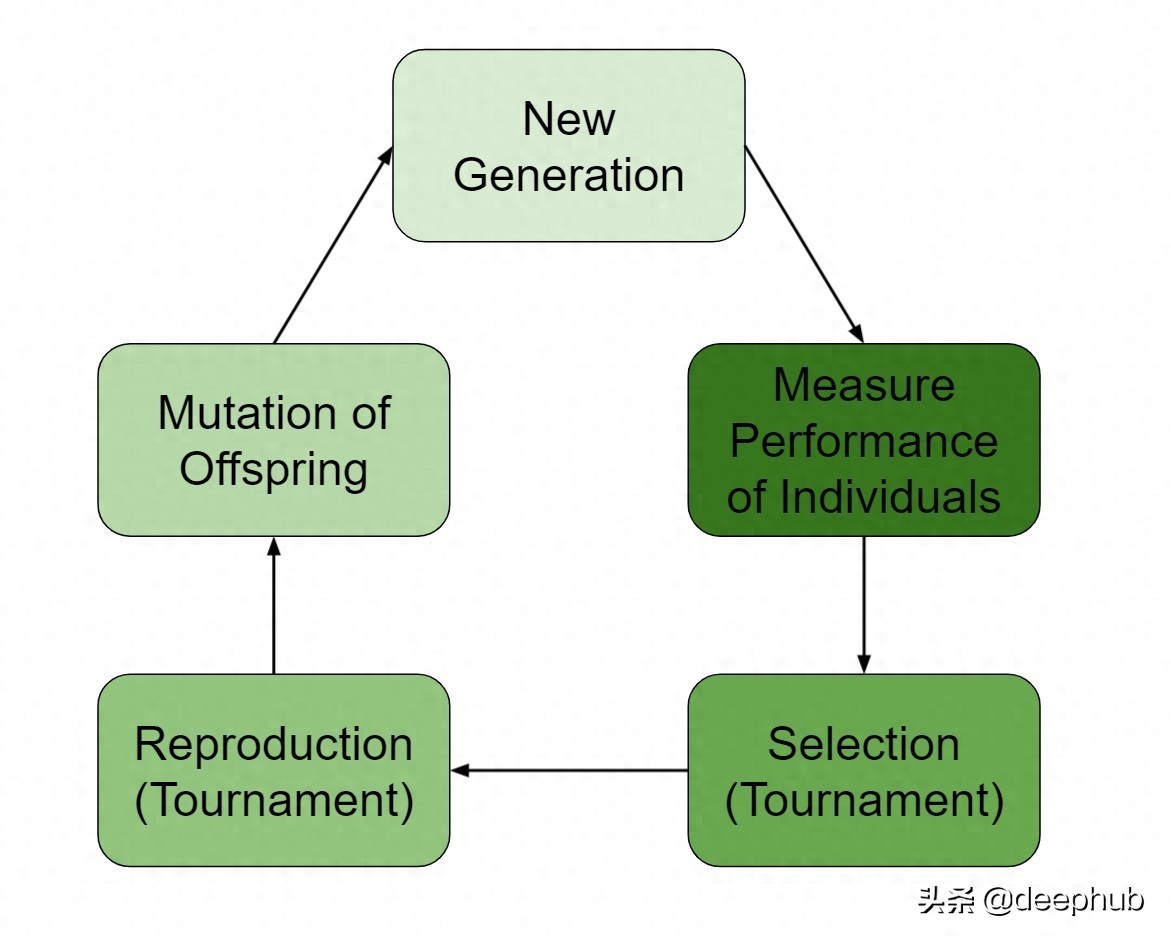
遗传算法运用进化原理来寻找最佳组合,在特征挑选方面,首要步骤是先从候选特征中挑选出部分特征,再将这些部分特征组合成初始种群。
从该群体里,借助任务相关的判断方法对部分样本实施检验。当群体所有个体都明确后,会举办角逐来选出哪些样本能进入下一轮。下一代的构成来自竞争的胜利者,对这些胜利者会进行组合,即用其他成功者的属性来优化胜利者的属性组合,同时也会进行变异,随机地增加或减少某些属性。
大致的步骤如下:
形成初始集体,为集体里每一个个体评定等级,借助比赛挑选部分用于繁衍的群体,挑选出需要遗传下去的基因片段,实施变异,重复这些步骤很多次,每一次构成一个世代
该算法运行一定数量的代之后,群体的最优成员就是选定的特征。
实际操作
该实验以 UCI 乳腺癌数据集为基准,该数据集共含 569 份记录和 30 项指标。基于此数据集,本人分别评估了全部特征、经遗传算法筛选的特征组合以及通过卡方检验选取的五个特征的表现情况。
下面是用于使用遗传算法选择最多五个特征的代码。
从sklearn.datasets模块中导入load_breast_cancer函数
在遗传选择库中导入遗传选择交叉验证功能
通过导入sklearn.tree模块,可以获得决策树分类器
import pandas as pd
使用numpy库,调用load_breast_cancer函数,获取乳腺癌数据集
创建一个数据框架,将数据集的数据部分作为数据源,将特征名称作为列标题
df的目标列赋值为数据的目标值
X等于数据框删除了目标列之后的所有其他列,按照列的方向进行删除
y是目标列转换成浮点类型的数据estimator是决策树分类器模型
model = GeneticSelectionCV(
estimator, cv=5, verbose=0,
评价方式为精准度,选取特征数量上限为五,
种群规模设为一百个个体,交叉概率确定为五十比百,
变异率是二十分之一, 代数为五十
组合独立概率等于五成
基因变异无关概率为四成,
比赛场数等于三, 未发生变化的世代数量为十,
caching=True, n_jobs=-1)
model = model.fit(X, y)
打印特性,包含模型支持列名,这些列名来自X的列属性,通过model.support_索引获取GeneticSelectionCV
初始种群由特征集的样本空间随机产生,规模为“n_population”。特征集的大小受限于参数“max_features”,此参数规定了每个特征子集可以达到的最大容量。
针对初始种群中的每一个个体,借助目标评估标准来判定其得分值。该评估标准是衡量指定估计方法运作效果好坏的依据。
挑选参赛者来决定哪些个体能够进入下一代。 参赛者的数目依据“tournament_size”来设定。 选拔过程从全部个体中选出若干个进行角逐,按照评分标准进行比拼。最终胜出的个体将被挑选为下一代的繁衍对象。
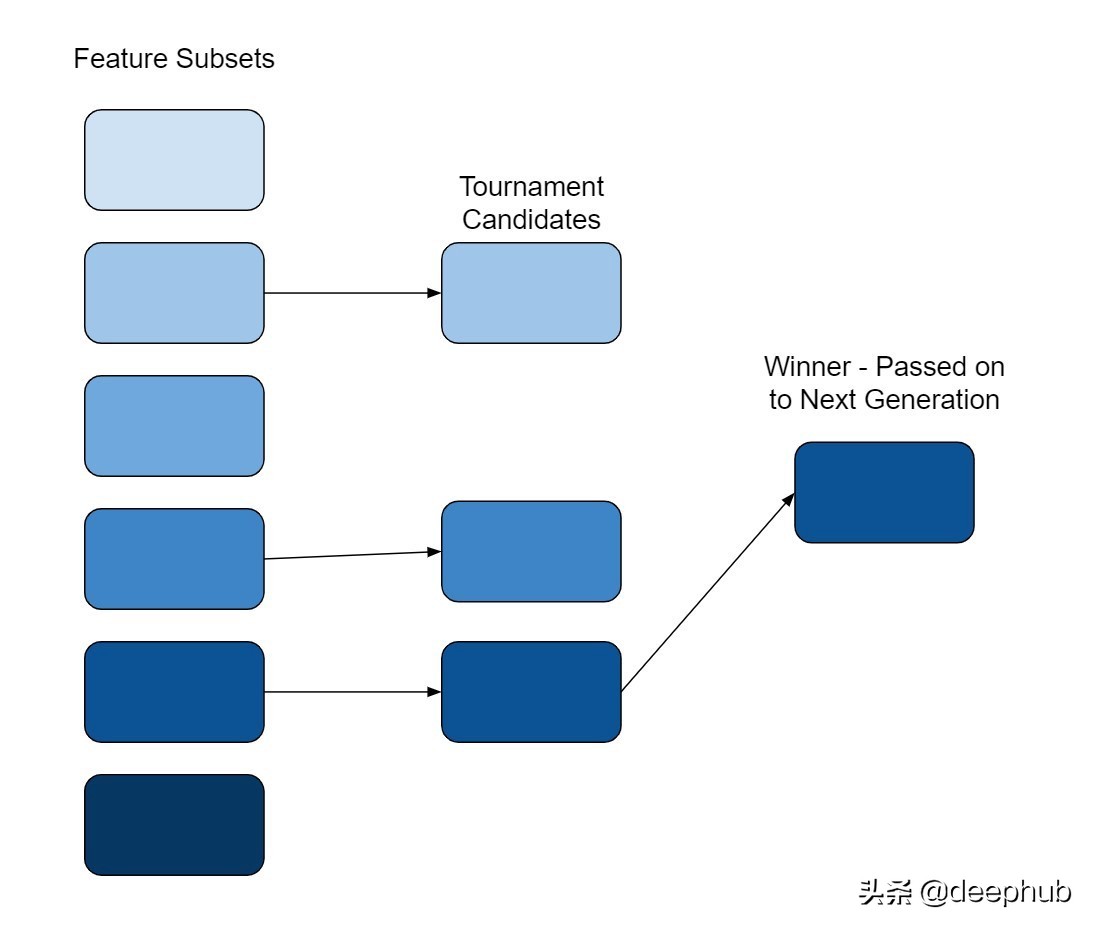
参赛者数量不宜过多。 值较高的情况下,一般挑选表现最优的个体。 这种做法不会选中能力较次的个体。 对能力较次的个体而言,虽然能获得短期的表现增强,但最终会造成整体水平的下滑,原因是这些能力不足的选项缺乏提升的机会。
自然选择
遗传密码记录在染色体上,通过繁衍活动部分基因片段由双亲传递给后代,新生个体因而拥有来自父母双方的基因特征,这种机制以“crossover_proba”这一数值衡量,该数值标示出从一次配对产生到下一次配对产生的几率kaiyun全站app登录入口,另设有参数“
该参数表示特征传递给子节点的可能性,是一个衡量标准,用于确定其是否会被分派到下一层级。
生物发展的重要特征是基因变异。这种变异能够减少算法在局部最优解上停滞不前的问题。每一代繁殖过程中,除了通过配对产生后代外,还会引入一个随机的基因改变。这种基因改变出现的几率由一个叫做“mutation_prob”的设定值控制。这个设定值和
融合“突变无关概率”,这为扩展属性集提供了契机。
值得留意的是,若把那个概率定得太高,算法就会变成随意挑选的过程。所以要把这个数值调整到比较低的程度。在每一代里面随机加入特征,能够起到很好的规范遗传过程的作用。
该遗传搜索方法设有“n_gen_no_change”指标,旨在观察群体最优个体连续多代保持稳定的情况。若出现此类情形,则表明搜索过程可能已收敛至局部最优解。此时需评估是否通过提升变异或交叉操作的概率,来促进群体多样性,从而寻求更优的解决方案。
结果
遗传算法与卡方检验筛选出的特征结果展示如下,同时提供了采用全部属性时的基准表现情况,这些数据均通过交叉验证方法获得,以准确率作为评估依据,特征数量已在括号内标明
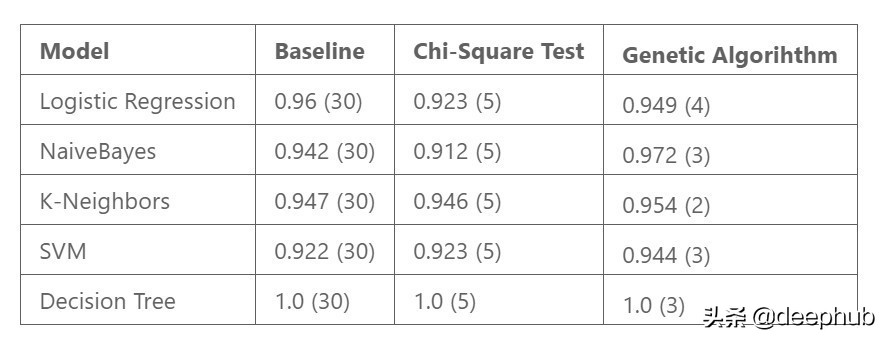
这些成果并非最终结论,却体现了遗传算法的优势所在。模型运作情况依托遗传算法筛选出的特征组合,这个组合始终比参照模型和卡方特征筛选出的组合表现更佳。唯独逻辑回归模型是个别情况,其结果依然可以相互比较。
另外,最优特征子集的规模小于五个特征中的最大规模,采用较少特征构建的模型比使用较多特征的模型更受欢迎,这是由于前者结构更为简洁kaiyun.ccm,并且解释起来更为方便。
总结
遗传算法非常通用,适用于广泛的场景。
这篇文章分析了如何借助 sklearn-genetic 包运用遗传算法进行特征筛选。这种算法同样显示出在超参数探寻以及创造式设计方面的良好性能。
遗传算法作为特征选择手段,有别于 sklearn 中现成的传统方法,具有独特实用性。这类算法的优化方式,与多数其他特征选择技术存在显著差异。其运作机制遵循纯粹的天然选择原理。
我鼓励数据科学家花时间在他们的工作中理解和实施遗传算法。
相关文章
-

云手机网页版 9个逆向思维小故事,幽默精辟
-
kiayun手机版登录app游戏登录入口.手机端安装.cc 2025年“按钮战争”即将来临(下)——国外电磁炮的最新进展.pptx
-
开·云app体育登录入口 2025年电磁炮路在何方.pptx
-
kiayun手机版登录.v1008.点进白给你1888.中国 9个逆向思维小故事,幽默精辟!
-
kiayun手机版登录app游戏登录入口.手机端安装.cc 电磁炮原理_原创精品文档.pptx
-
kiayun手机版登录app游戏登录入口.手机端安装.cc 个逆向思维小故事
-
kiayun手机版登录app游戏登录入口.手机端安装.cc 电磁炮的基本原理 -回复.pptx
-
kiayun手机版登录打开即玩v1011.速装上线体验.中国 空气动力学“伯努利原理”课件,风洞.ppt