人类偏好的“可塑性”,从博弈说起
研究者借助让参与实验者做出决定的方式,来探明他们的倾向性。这种方法在物件构造、商业推广以及网络购物平台等领域,获得了普遍的应用。
汽车制造者向体验者展示多款配置各异的车辆,包括多种涂装色彩、座椅布局、行李箱容积、动力电池规格以及杯托装置等,目的是探究消费者重视哪些车辆特性,并查明他们愿意为这些特性付出多少代价。
医学界亦有显著用途,外科医生在权衡是否实施截肢手术时,或许要权衡患者对行动自由与生命时长的取舍,披萨店同样关注顾客愿为香肠风味比普通款式多付多少钱
如何寻找奖励信号优化复杂行为?
选择倾向一般只涉及在众多事物间做出的单一决定,我们设想这些事物对被考察者来说价值是显而易见的,但目前不明白怎样将其延伸至对未来生活的倾向上,为此我们(以及机器)必须从长期的行为记录中获取知识,这包含有多种选择和不确定后果的行为
1997年春季,我同迈克尔·迪金森与鲍勃·弗尔就如何借助机器学习理念来解析动物活动模式交换了看法,迈克尔深入探究了果蝇翼部活动规律,鲍勃则对奇异爬行动物情有独钟,他特地为蟑螂配备了一台微型跑步设备,旨在考察其步态随运动速率调整的演变情形。我们觉得,借助强化学习来训练机器人或模仿昆虫,能够复制这些复杂动作。我们遇到的问题是kaiyun全站登录网页入口,不清楚该采用何种奖励机制,也不明白苍蝇和蟑螂在追求什么目标。缺少这些信息,我们就无法运用强化学习来培育虚拟昆虫,因此陷入两难境地。
当天,我从位于伯克利的那栋住宅前往社区商店。沿途有一段坡路,我察觉到,这段坡度让我的行走姿态出现些微调整,我想多数人都会如此。而且,数十年来数次轻微地震导致路面变得凹凸不平,行走时人的步伐因此产生进一步变化,因为地面高度难以预料,我的脚会抬高少许,落地时也显得不那么僵硬。
我琢磨着这些日常见闻,发觉我们理解有误。强化学习是靠奖赏引导行动的,可我们真正需要的是探寻行动本身对应的奖赏机制。苍蝇和蟑螂早已展现出某些行为模式,现在该弄清楚这些行为究竟在追求怎样的激励因素。
换句话说,我们应当采用逆强化学习方法。(此前我并不清楚,存在另一个相关课题,它被称作“马尔科夫决策过程的结构式估计方法”,这是诺贝尔奖得主汤姆·萨金特在70年代末期开创的一个研究方向。)此类方法不仅有助于说明生物的活动,也能预知它们在陌生场景中的反应。
或许,认识逆强化学习算法最直接的方式是:观察者先对真实的奖励函数有一个不清晰的认知,接着通过观察更多行为来逐步完善这个认知,使其更加准确。或者,借助贝叶斯理论来阐述:从可能存在的奖励函数的初始概率分布出发,再依据不断积累的证据来调整奖励函数的概率分布情况。
如何让机器将人类行为转化为人类偏好?
强化学习现在已是建立高效智能体系的关键手段,不过它采用了一些简化的前提设定。
一旦机器人通过观察人类掌握了奖励机制,便会依据该机制行事,从而能够完成固定的工作。在驾驶汽车或操控直升机这类任务中,这种方式并无障碍,然而在处理喝咖啡这种情境时却行不通:一个通过观察我早晨行为模式而得知我(偶尔)需要咖啡的机器人,不该知晓它自身是否渴望咖啡。处理这个议题十分便捷,关键在于让机器人将个人好恶同人类挂钩,而非视自身为参照物。
逆强化学习的又一个简化前提是,机器人正在观看人类处理单一决策任务,比如,设想机器人在医学高等院校,通过观摩人类高手的操作来掌握外科手术技巧,该算法认为人类通常以最优状态进行手术,仿佛机器人并未在场
实际情况并非这样:外科医生的目标是促使机器人像其他医学学子那样迅速掌握技能,这将显著影响其操作方式。机器人会边操作边说明当前步骤kaiyun官方网站登录入口,会提示可能出现的失误,例如切口过深或缝合过紧,也会阐述手术中若遇突发状况应如何应对。独自实施手术时,这些举措毫无价值,所以逆向强化学习办法将无从说明这些举措所流露的倾向。
因此,我们应当把逆强化学习的应用范围从单一智能体扩展到多个智能体,具体而言,我们必须要研发一种学习方案,这种方案必须能够适应人类与机器人在同一环境中共存且彼此作用的情形,并且能够有效运作。
一个人与机器人共存于某个场景时,便涉及博弈学原理。该学说的初始构想设定人类存在倾向性,其行为以此为基础。机器人无法洞悉人类的倾向,却始终力图令其满意。此种情形称作“支援性对抗”,因本质要求机器人必须对人类提供支持。
这个辅助博弈具体展示了我在《AI新生》里阐述的三个核心观点:机器人的根本任务在于顺应人类的意愿,它一开始并不清楚人类的意愿具体是什么,而且它能够通过观察人类的活动来获取更多信息。辅助博弈最吸引人的地方在于,机器人借助处理博弈任务,可以独立领悟怎样把人类的活动转化为对人类意愿的理解。
机器人罗比会梦见回形针吗?
回形针博弈可视为辅助博弈的示范。此游戏极为简便,参与者哈里特存在意愿,需向对手罗比传递部分个人倾向资讯。罗比具备解读能力,由于该游戏规则他能掌握,故能明白哈里特为何发出此类信息,进而知晓其真实倾向。
操作流程参见图12,其中包含回形针与订书钉的制造环节,哈里特的倾向性借助一个效益公式来体现,此公式关联着所造回形针与订书钉的多少,两者存在特定的“兑换比例”。
她或许会认为回形针值45美分,而订书钉值55美分,这两个价格的总和固定为1.00美元,关键在于它们之间的比例关系。所以,当制造10个回形针和20个订书钉时,哈里特能够获得10乘以45美分加上20乘以55美分的收益,总计15.50美元。机器人罗比起初对哈里特的喜好毫无头绪:她赋予回形针的价钱在零美元到一美元之间,数值分布完全相同。哈里特率先决定,她能够挑选生产两枚回形针,或者两枚订书钉,抑或是各生产一枚。随后,罗比着手决定,他可以选择制造九十枚回形针,或者九十枚订书钉,又或者各生产五十枚。
如果哈里特独立完成这件事,用了两个订书钉,花费为1.10美元。然而罗比在一旁观察kaiyun全站app登录入口,从她的行为中获取了知识。罗比具体习得了什么,要看哈里特的选择方式。哈里特的选择方式,又取决于罗比如何解读她的行动。因此,我们似乎陷入了一个循环困境!博弈论问题中常见此类情况,这也是纳什提出纳什均衡概念的根本原因。
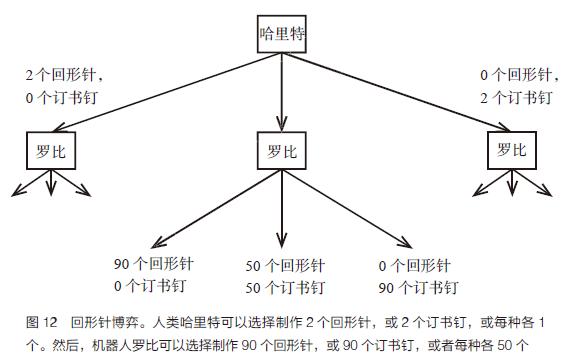
寻求一个恰当的解决方法,我们得为哈里特和罗比制定计划,如果任何一方的计划固定不变,那么双方都不会去调整自己的计划。哈里特的一个计划是,按照她的喜好,决定要制作多少个回形针和订书钉;罗比的一个计划是,参照哈里特的行动,决定要制作多少个回形针和订书钉。
事实证明,似乎只有一个均衡解。
• 哈里特根据她对回形针的估价做出如下决定:
如果价值低于44.6美分,我就制作0个回形针和2个订书钉;
如果价值在44.6-55.4美分之间,我就每种各制作1个;
如果价值大于55.4美分,我就制作2个回形针和0个订书钉。
• 罗比回应如下:
倘若哈里特生产零根回形针,并且打造两枚订书钉,那么我将制作九十枚订书钉。
如果哈里特每种各制作1个,我就每种各制作50个;
哈里特若生产两枚曲别针,不生产任何夹子,那么我将仅制作九十枚曲别针。
运用这一方法,哈里特实际上在借助一种简易的符号体系(若愿意,亦可称之为一种沟通方式)向罗比传递她的倾向性,这种简易的符号体系源自均衡分析的研究成果。仿照外科医生指导的情境,单一智能体的逆向强化学习技术无法辨识这种符号体系。还应该留意,罗比其实并不完全清楚哈里特的喜好,不过它已经掌握了足够的信息去为她做出最恰当的回应,换言之,它的表现仿佛真的了解哈里特的倾向。如果基于某些前提,并且哈里特确实在正确地参与游戏,那么我们能够论证罗比对哈里特是有益的。
人们同样能够提出疑问,罗比会像一名认真学生那样进行提问,哈里特则像一位优秀导师那样向罗比说明需要规避的误区,这些举动产生的原因,并非我们设定了让罗比听从哈里特的程序,而是因为这是哈里特与罗比参与的合作性游戏中最理想的应对方式。
我们另有一些途径能够改进模型,或者将模型置入繁复的决策情境里。不过我确信,一个中心思想,即有益的、遵从的行为与机器对人类偏好认知的模糊性之间的紧密关联,不会因这些深化和复杂化而动摇。
此篇内容源自斯图尔特·罗素的著作《AI新生》,由中信出版集团于2020年10月出版发行。
实习/全职编辑记者招聘ing
欢迎加入我们,亲身感受一个权威科技媒体的工作流程,深入探索最具发展潜力的领域,与众多国际顶尖人才共同进步。办公地点位于北京清华东门附近,请在大数据文摘官方网站的互动平台输入“招募”获取更多信息。有意者可将个人资料发送至zz@bigdatadigest.cn。